CosyVoice 是一个多语言大型语音生成模型,它提供推理、训练和部署的全栈能力。你可以使用它进行多语言的语音生成、零样本语音克隆、使用自然语言控制语音语调等
安装CosyVoice
-
打开应用商店,找到CosyVoice,即可一键安装部署CosyVoice
注意
首次安装时,CosyVoice需要先下载必需的模型文件(大约50GB)。这一安装过程耗时会因为您的网速而有较大差异,请你耐心等待安装完成
-
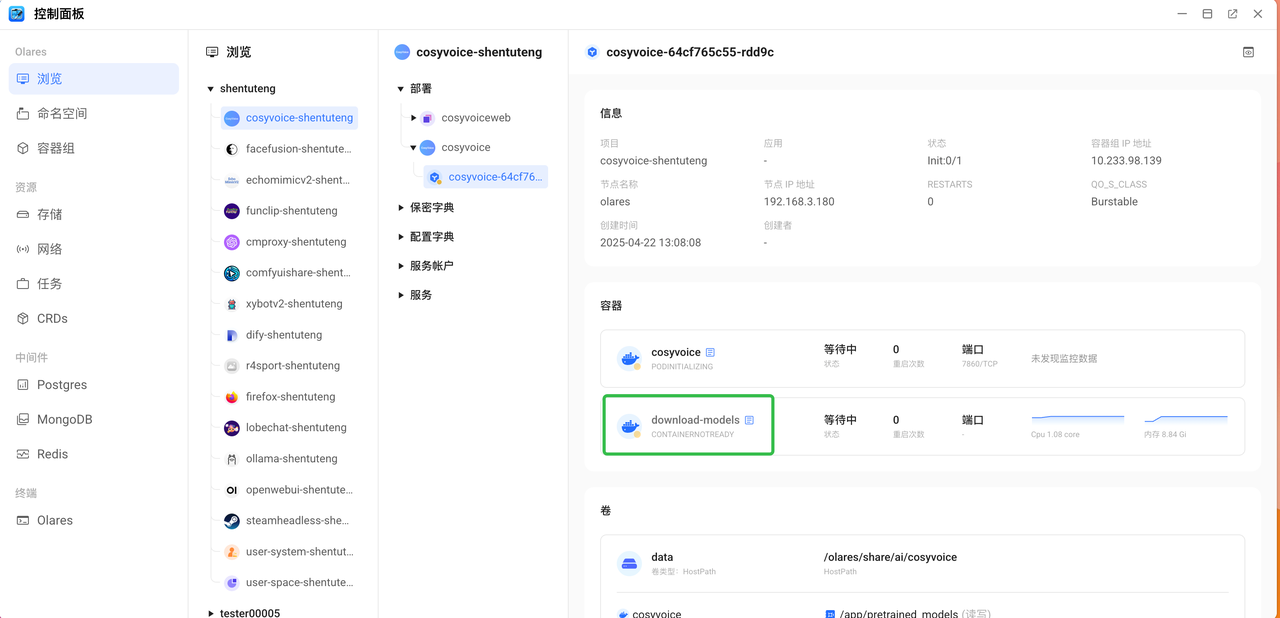
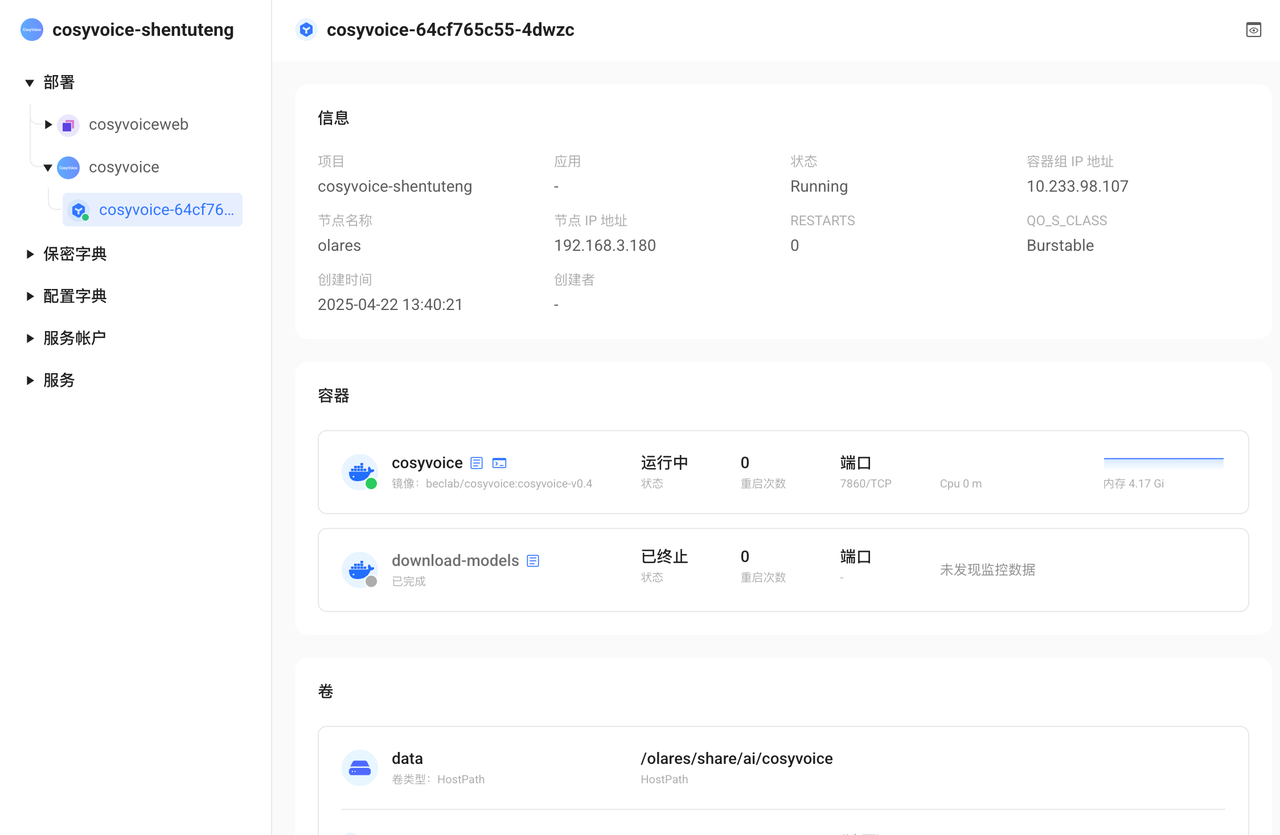
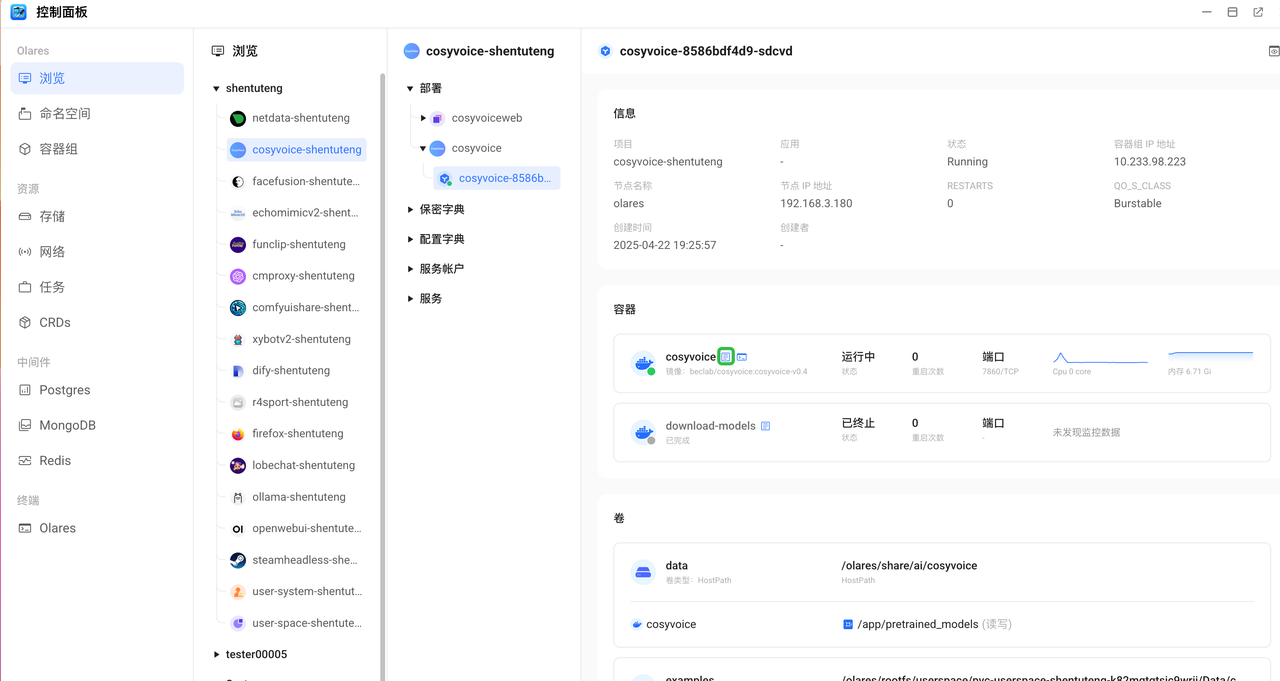
如果长时间安装未完成,您可以打开 控制面板,找到 cosyvoice ,查看部署下面的download-model容器是否运行正常。如果像下图1 所示,显示等待中,则表明下载仍在进行中。如果像图2所示,容器显示为已完成,则表明模型下载工作已完成。
-
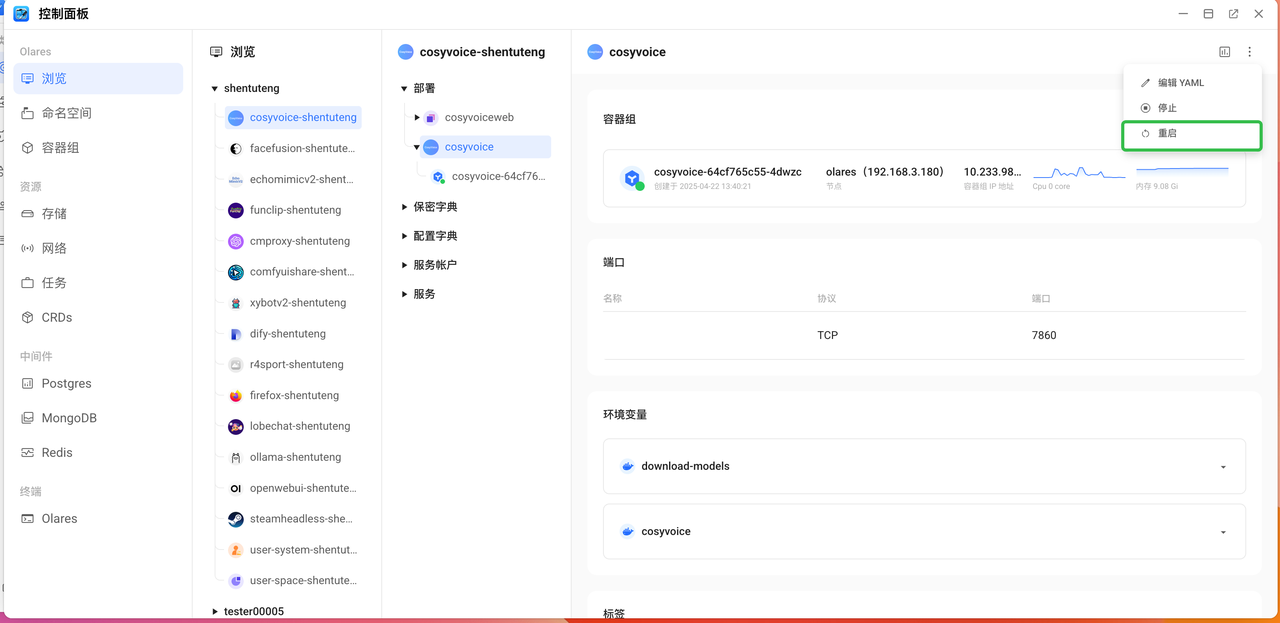
如果下载容器显示失败,您可以尝试重启再试一次
-
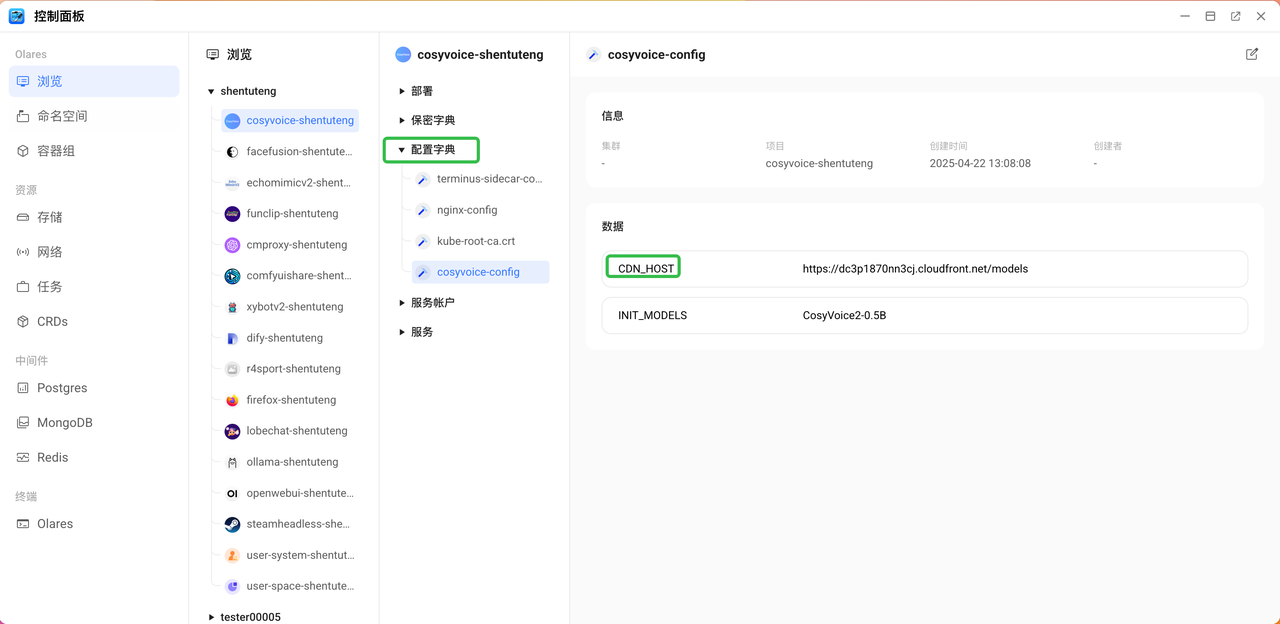
如果下载速度过慢或多次下载失败,可能是您和模型下载cdn服务器之间网络不畅导致的。您可以打开控制面板,找到 cosyvoice ,打开配置字典
consyvoice-config。国内用户可以点击右上角的编辑按钮,将CDN_HOST的值改为https://cdn.joinolares.cn/models,然后按上一步方法重启容器。
使用CosyVoice
使用预训练音色进行语言生成
CosyVoice 默认使用
CosyVoice-300M模型启动,该模型内置7种音色。CosyVoice2-0.5B/CosyVoice-300M-Instruct暂无预训练音色配置,暂时使用CosyVoice-300M的音色文件替代。已知问题:
CosyVoice2-0.5B/CosyVoice-300M-Instruct中的男性音色仍然是女声。CosyVoice-300M的音色文件在CosyVoice2-0.5B可能效果较差,请酌情使用。
-
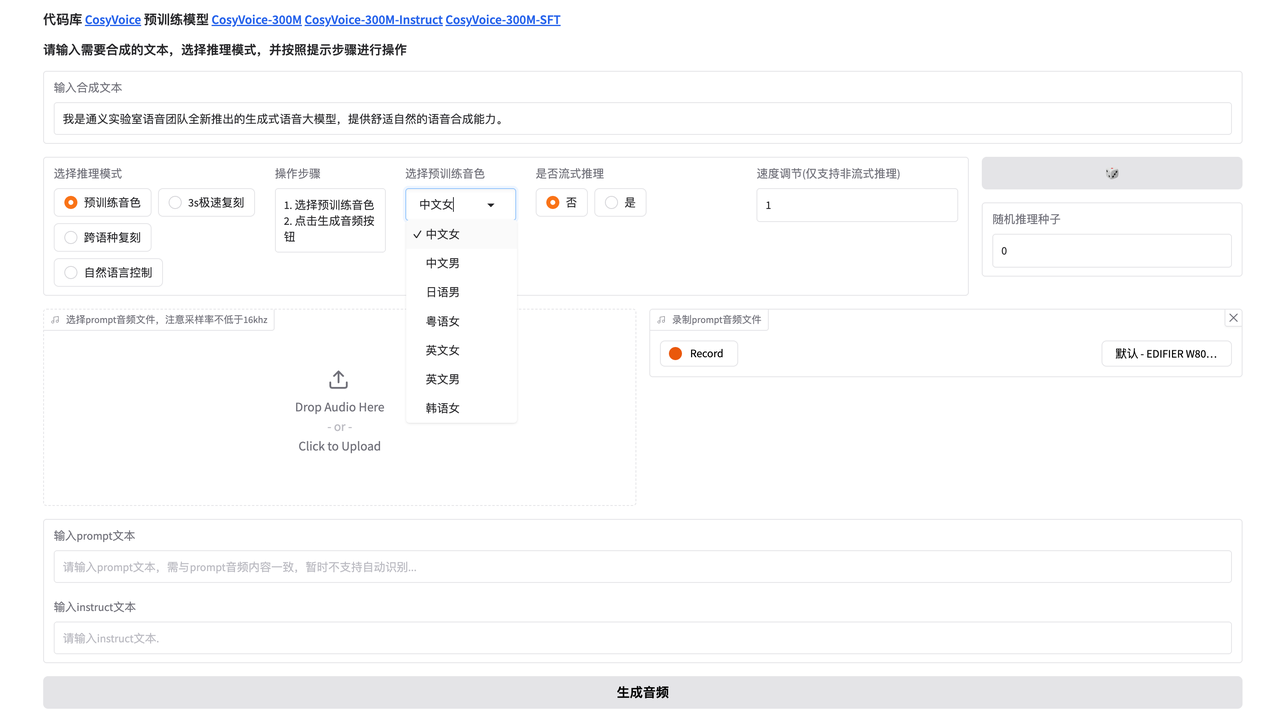
模式选择预训练音色
-
在上方 输入合成文本处 输入要生成语言的文本,选择音色。点击生成音频即可。
-
可以选择流式推理,此模式下会逐段输出音频。但实测在衔接处存在卡顿、声音强度变化等问题。不建议在输出最终音频时使用流式推理
-
你还可以选择速度调节或随机修改推理种子抽卡。此处的速度调节就是倍速播放,如果希望加快或减慢语速,建议使用自然语言控制通过instruct文本调节,效果更自然。
-
语音克隆
语音克隆需要使用
CosyVoice-300M或CosyVoice2-0.5B模型。如需使用CosyVoice2-0.5B模型,请确认已下载好所需模型,然后参照下文切换模型部分修改启动模型。
-
模式选择3s极速复刻
-
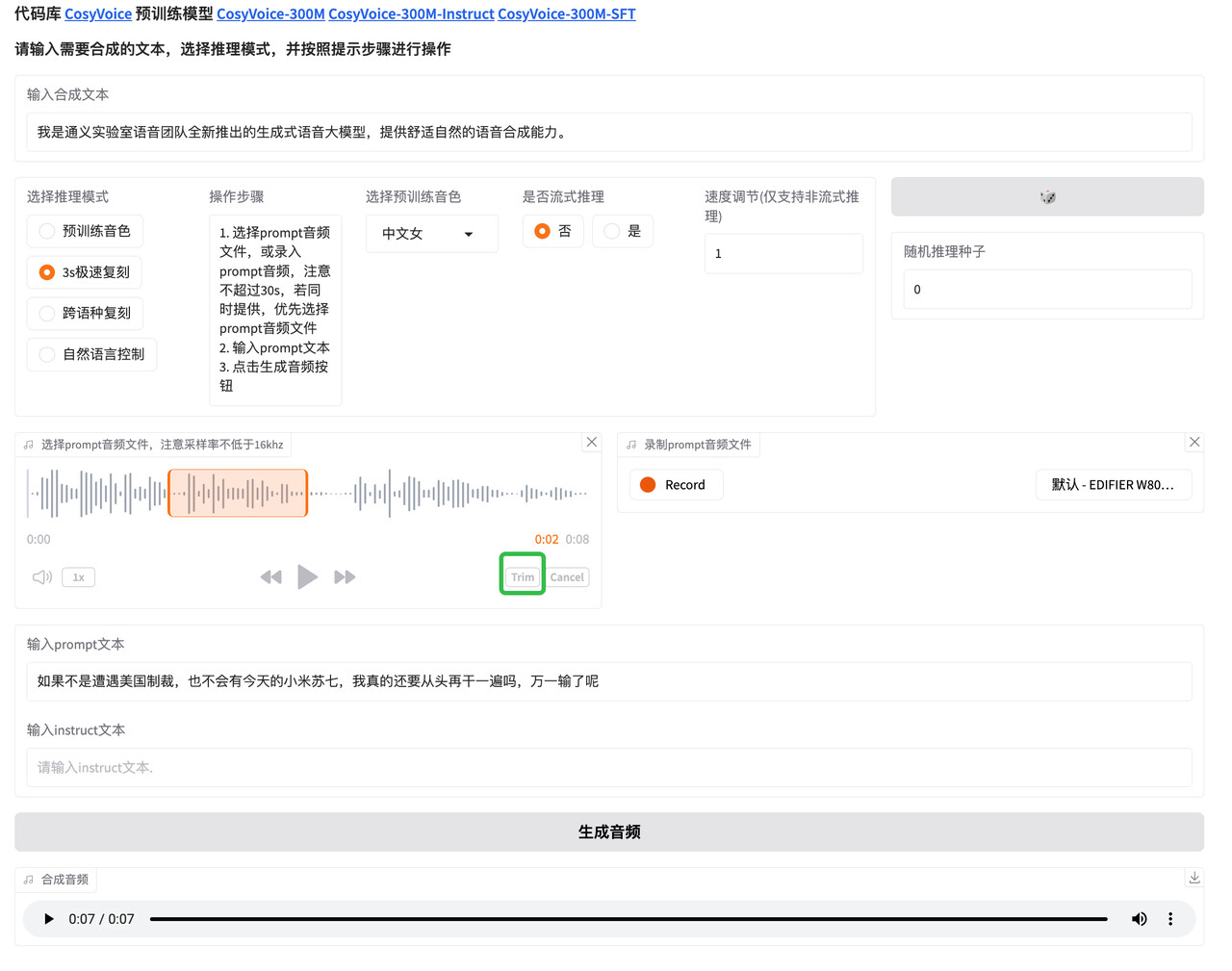
在prompt音频处上传参考音频,或者在右侧录制音频
- 参考音频时长不超过30s,只有单人说话,最好没有其他背景音乐、噪音等
- 建议使用mp3或wav格式音频,但任何音频都有可能解码失败。如果遇到报错,可以尝试转换格式后再上传。
- 点击右下角剪刀按钮,可以裁减参考音频的头尾内容。拖动鼠标设置需要保留的音频区间,点击Trim按钮保存剪辑后的音频
-
在prompt文本处,输入参考音频对应的文本转录。
- CosyVoice目前暂不支持自动转录,您可以手动输入或使用其他工具转录。
-
在上方 输入合成文本处 输入要生成语言的文本,效果示例:
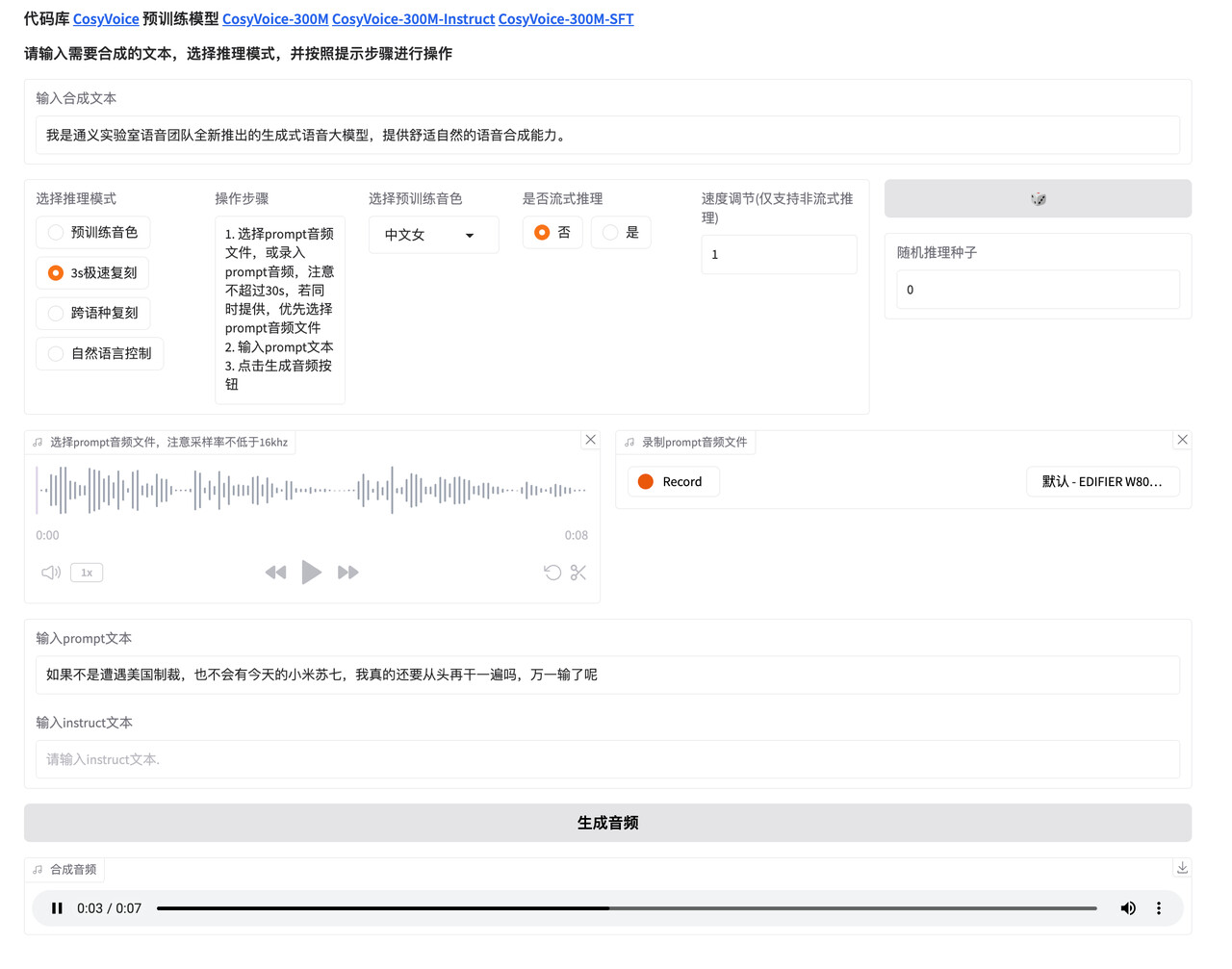
prompt文本:
如果不是遭遇美国制裁,也不会有今天的小米苏七,我真的还要从头再干一遍吗,万一输了呢prompt音频:
CosyVoice1:
CosyVoice2:
跨语种复刻
跨语种复刻需要使用
CosyVoice-300M或CosyVoice2-0.5B模型。如需使用CosyVoice2-0.5B模型,请确认已下载好所需模型,然后参照下文切换模型部分修改启动模型。
-
模式选择跨语种复刻
-
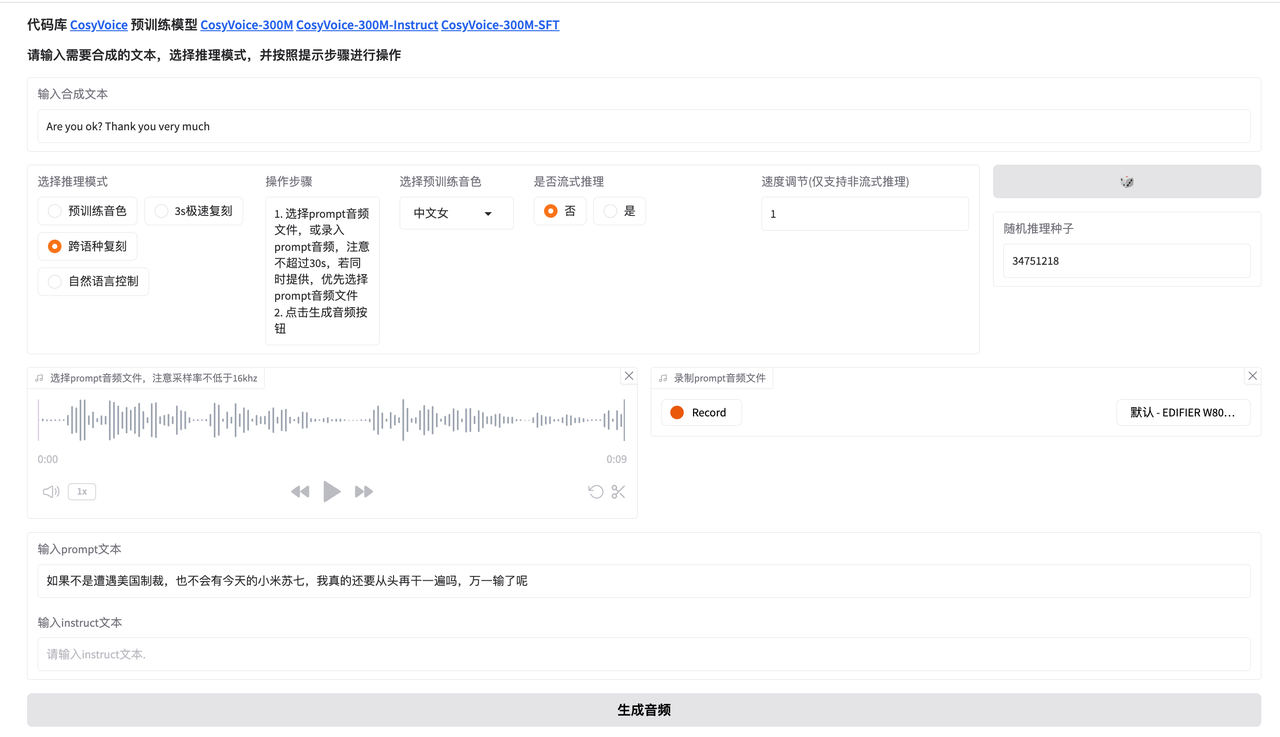
跨语种复刻在操作上和语音克隆一致,只是在输入合成文本处 需要输入目标语言的文本,目前支持中文、英文、日文和韩文。
-
效果示例:
语言控制
CosyVoice支持使用自然语言控制和控制词(如[laughter])对合成语言进行控制。自然语言控制需更换为
CosyVoice-300M-Instruct模型,请参照下文切换模型部分修改启动模型其他注意事项
- 目前暂不支持使用WebUI对
CosyVoice2-0.5B进行自然语言控制。请等待官方更新。- 方言配音的自然语言控制仅限
CosyVoice2-0.5B- 控制词句中控制,仅在
CosyVoice2-0.5B上支持
-
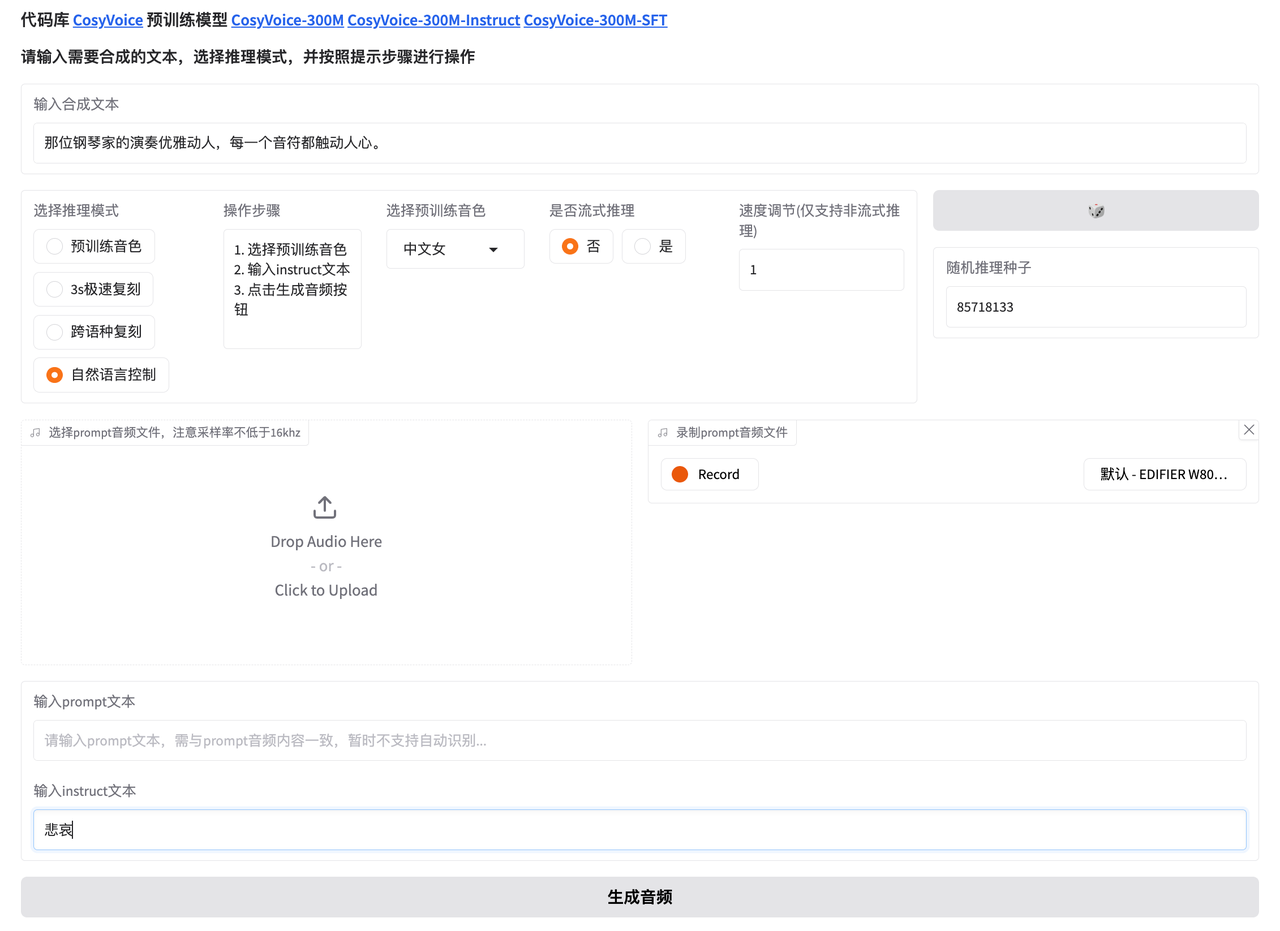
模式选择自然语言控制。
-
在上方 输入合成文本处 输入要生成语言的文本,在下方instruct文本处输入控制指令。
-
你可以输入朗读的语气、语速、情绪等进行直接控制,也可以描述配音角色的特点等。
-
自然语言控制有失效的概率,你需要修改随机种子进行抽卡
-
控制失效的情况包括但不限于:朗读instruct文本、吞字、漏字、控制输入无效
-
在instruct文本后加上<|endofprompt|>有时可以改善控制文本的效果
-
-
效果示例:
文本:
那位钢琴家的演奏优雅动人,每一个音符都触动人心。悲伤:
欢快:
-
-
句中控制词控制
- 使用
CosyVoice2-0.5B模型时,你可以在合成文本中添加<laughter></laughter><strong></strong>[laughter][breath]等控制词,在指定位置添加笑声、呼吸停顿等。
- 使用
训练克隆的音色文件
暂不支持通过UI进行音色训练,脚本操作可参考官方文档中的Advanced Usage部分。其中example文件在 数据 > cosyvoice 目录下
切换模型
CosyVoice提供了多个模型供不同场景使用。应用目前默认使用CosyVoice-300M,如需自然语言控制、方言等能力,您需要切换CosyVoice的启动模型。
- CosyVoice-300M:CosyVoice1.0的基础模型,建议在零样本语音克隆和跨语言合成时使用。资源消耗较低。
- CosyVoice-300M-Instruct:为基于指令的合成而设计,支持自然语言控制和使用预训练音色生成语音
- CosyVoice2-0.5B:全能的2.0模型,支持零样本语音克隆、跨语言合成、自然语言指令、方言。但目前WebUI未能完全支持,且资源开销优化不佳,经常存在爆显存的情况。
- CosyVoice-300M-SFT:主要用于SFT推理时使用,可以更好地控制语音特性和风格。一般不建议在WebUI中使用。
切换模型的具体方法为:
-
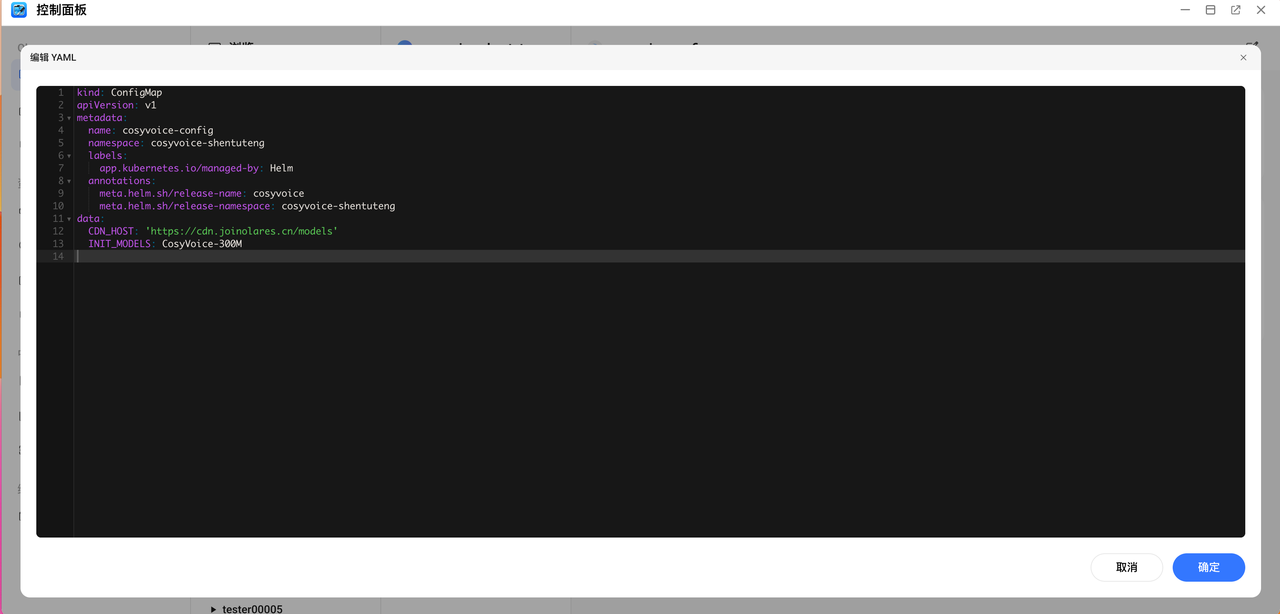
打开控制面板,找到 cosyvoice ,打开配置字典
consyvoice-config。将INIT_MODELS的值改为以下4个模型之一:CosyVoice2-0.5BCosyVoice-300MCosyVoice-300M-SFTCosyVoice-300M-Instruct
-
修改完毕后,重启容器。
异常处理
目前使用CosyVoice2-0.5B时可能会经常出现CUDA OOM的错误。如果看到页面上出现Error提示,可以打开控制面板,找到 cosyvoice ,查看部署下面的cosyvoice容器日志。如果出现类似以下内容的错误日志(CUDA out of memory),您可以通过重启Pod来释放显存。

卸载CosyVoice
要完全移除CosyVoice以及所有相关的模型数据,您需要
-
应用商店卸载 CosyVoice
-
删除应用示例数据:进入 文件管理器 > 数据 目录下删除cosyvoice目录。
-
删除模型文件:进入 文件管理器 > 外部设备 > ai > 目录下删除cosyvoice目录。