本教程将指导你如何在 Olares 里使用 Heygem 提供的 API 接口来生成数字人视频。
准备条件
- 确保 Olares 在正常运行。
- 确保你的系统已经安装了 ffmpeg。ffmpeg 是一个用于处理音视频数据的命令行工具,我们将用它来分割视频文件。你可以从 ffmpeg 官网下载并安装。
安装配置应用
-
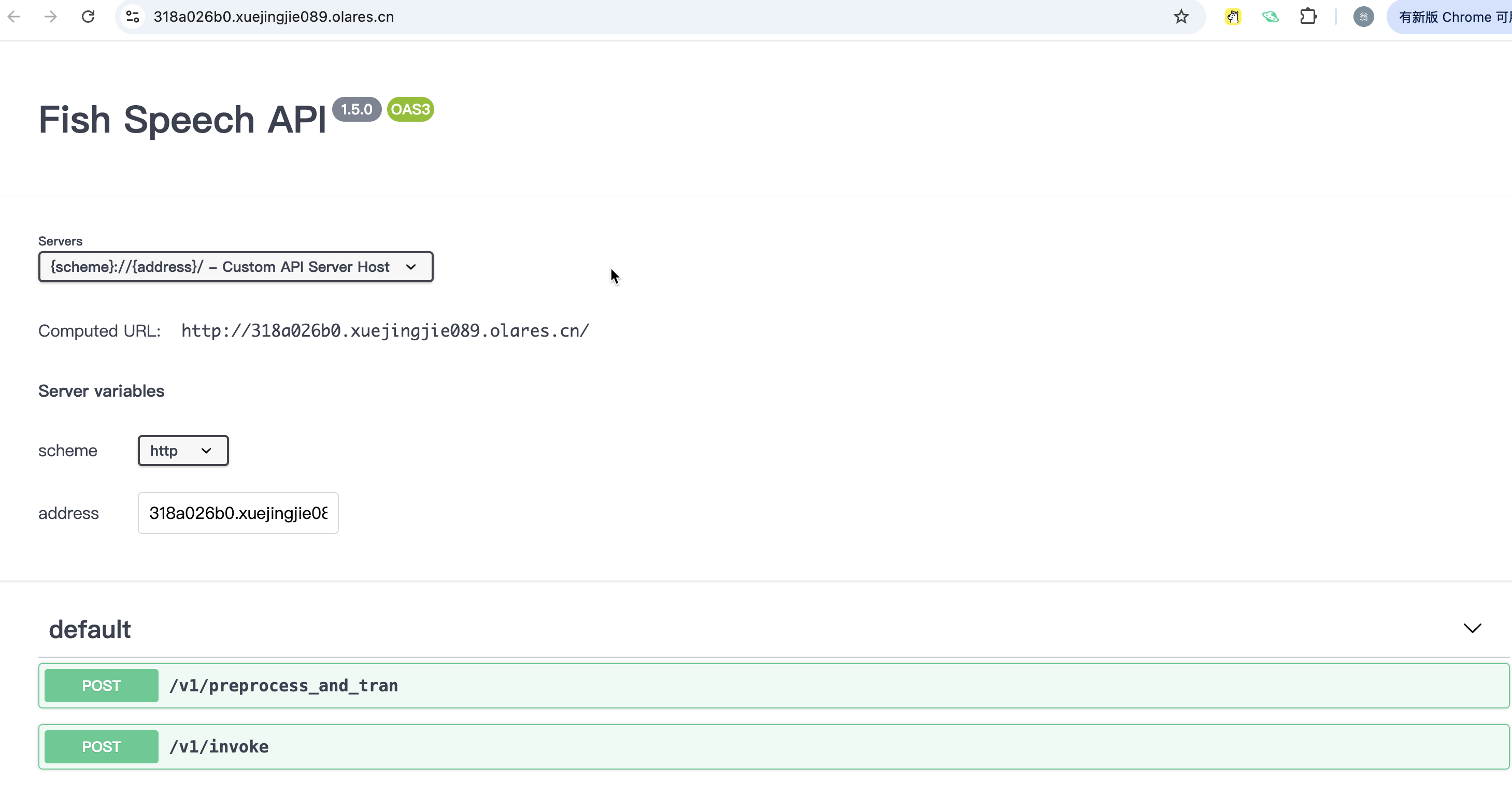
获取 Heygem Server: 打开 Olares 应用市场,在 "实用工具"类别中找到并安装 Heygem。安装完成后打开 Heygem,看到接口列表说明安装成功。同时可从页面获取 Heygem 域名:
https://318a026b0.{yourOlaresID}.olares.cn/。 -
获取 Hoppscotch: 在 Olares 应用市场的 "实用工具"类别中找到并安装 Hoppscotch。
-
导入 Heygem API 接口到 Hoppscotch:
a. 打开Hoppscotch,在右侧集合选项里,点击 Import/Export 按钮,并选择 Import from Hoppscotch。
b. 将 Heygem API 配置文件
heygem.json导入。导入成功可以看到新增集合下列出的 Heygem 接口选项。
-
安装 Hoppscotch Chrome 插件:在 Chrome 应用商店搜索并安装 Hoppscotch 插件。
-
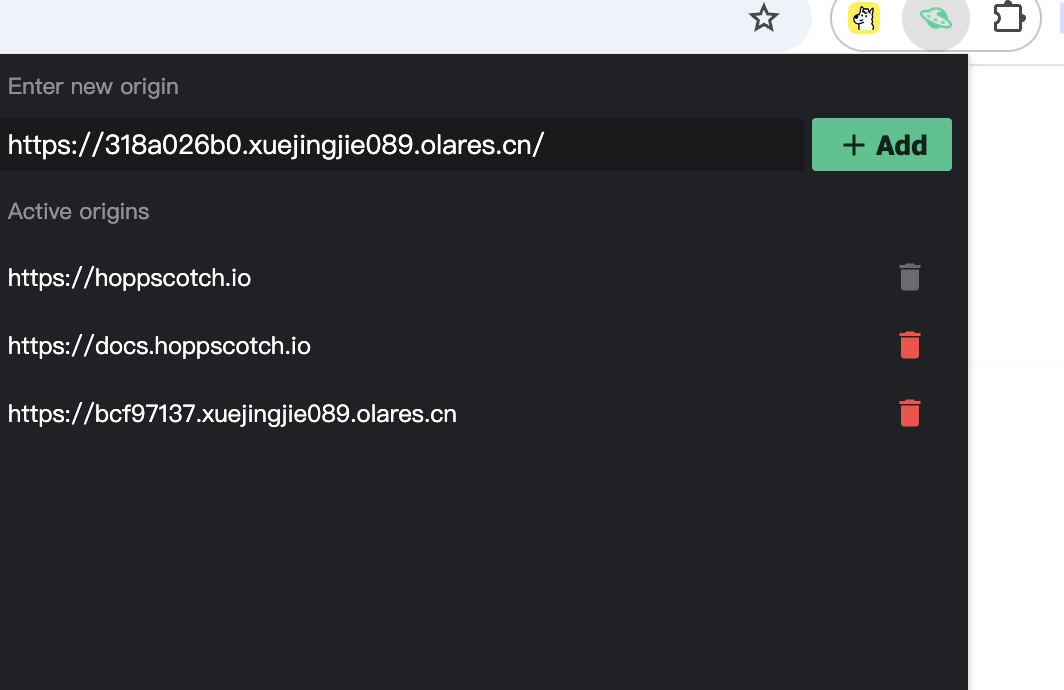
将 Heygem Server 的域名添加到 Hoppscotch 插件中,让 Hoppscotch 能够访问 Heygem Server。
准备素材
这一步需要需要一个用于数字人合成的原始视频,并将原始视频分割成静音视频和音频文件。
-
使用 ffmpeg 命令将素材视频的音视频分离:
ffmpeg -i input.mp4 -c:v copy output_video.mp4 -c:a libmp3lame -q:a 4 output_audio.mp3注意:
生成的output_audio.mp3文件需要转换为wav格式。直接使用 mp3 格式可能会导致 Heygem 报错。具体的转换方法可以使用其他音频处理软件或 ffmpeg 命令。 -
将转换后的音频文件
output_audio.wav通过 Olares 的文件管理器上传至以下路径:Data/heygem/heygem_data/voice/data/temp/
模型训练
-
在 Hoppscotch 右侧的 Heygem 接口选项下,选择调用
v1/preprocess_and_tran接口进行模型训练。
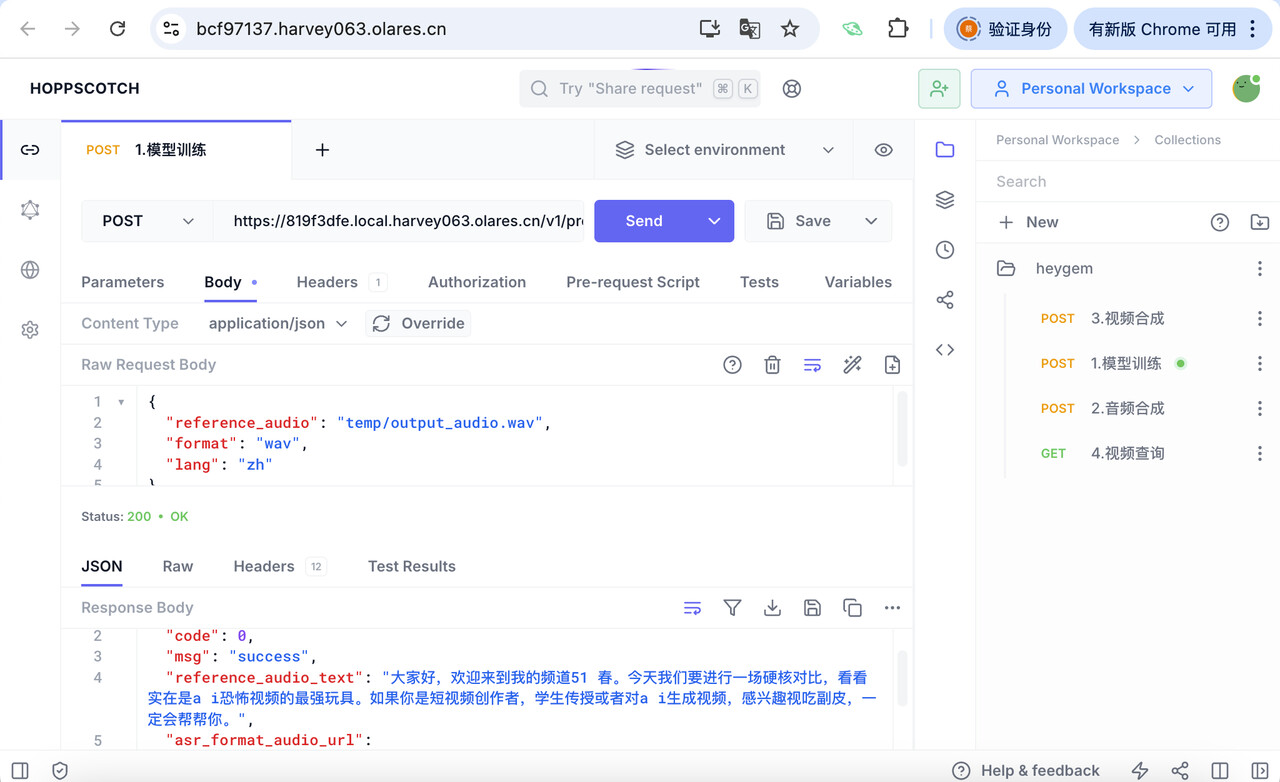
- Body 配置:
- reference_audio:上传到 Olares files 的音频文件路径。
- format": “wav”:音频文件格式,设置为 “wav”
- lang:请替换为你的音频语言 (例如: zh, en)
- 点击 Send 发送请求。返回模型训练的结果Response:返回包含 reference_audio_text 和 asr_format_audio_url 等信息的 JSON。
音频合成
-
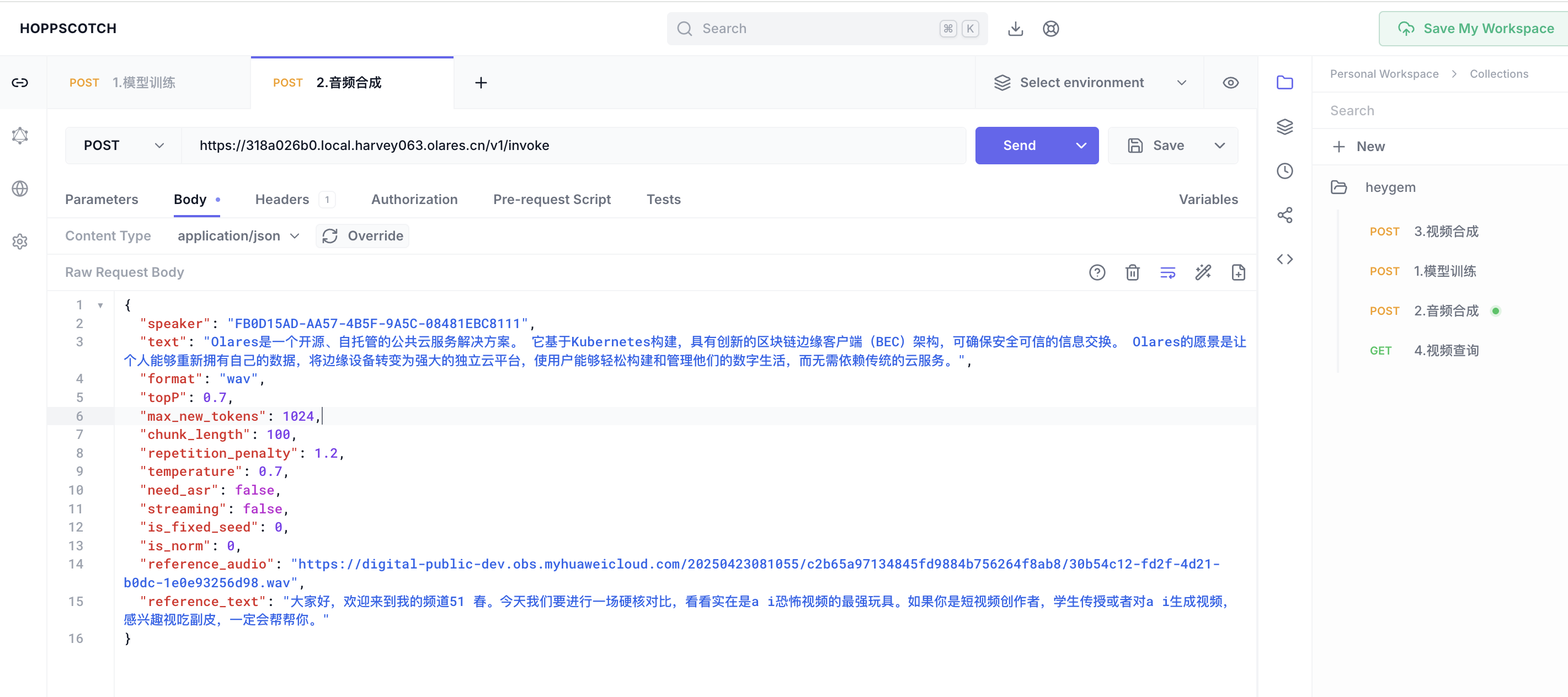
在 Hoppscotch 右侧的 Heygem 接口选项下, 调用
v1/invoke接口合成音频:- Body 配置:
- text 是自定义的文本(想让数字人说的话)
- speaker 是随意生成的UUID,
- reference_audio 和 reference_text 使用上一步模型训练接口的返回值。
- 其余参数固定不变
- Body 配置:
-
点击发送。成功后会返回合成的音频文件 (
new.wav)。
视频合成
-
将合成的音频文件 (new.wav) 和静音视频文件 (output_video.mp4) 使用 Olares 文件管理器上传至以下路径:
Data/heygem/heygem_data/face2face-data/temp/ -
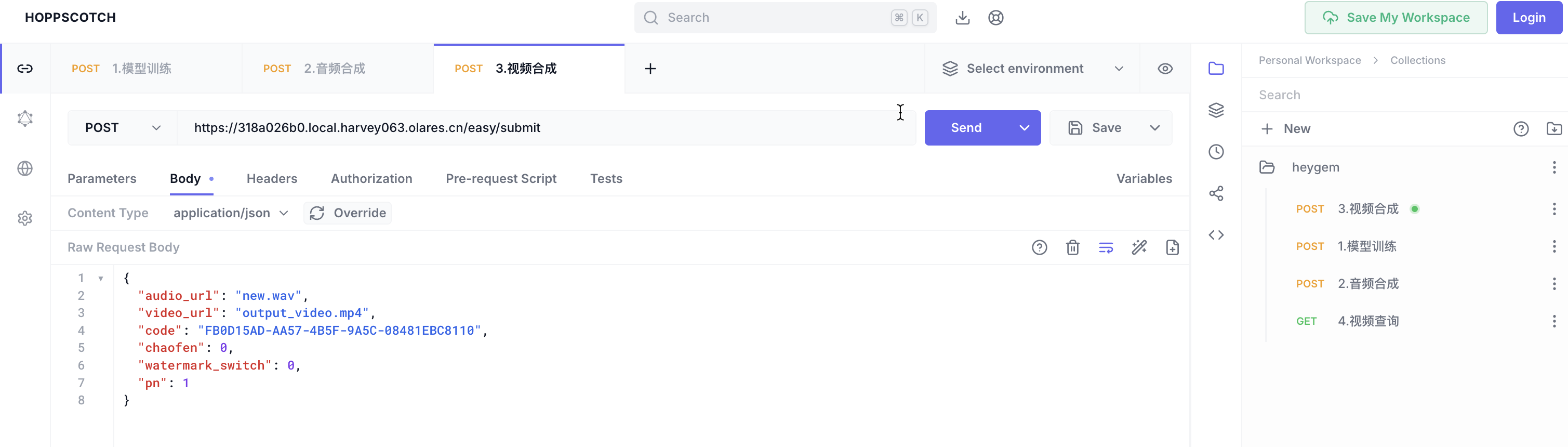
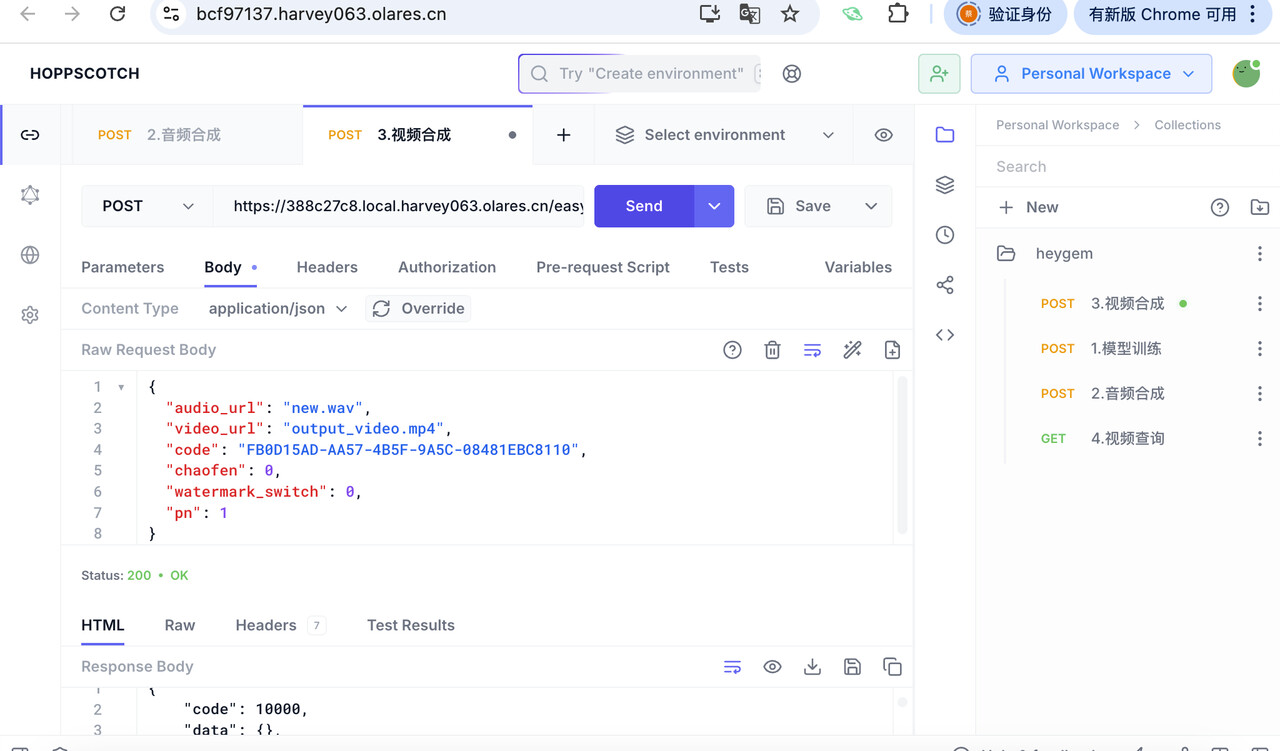
使用 Hoppscotch 调用
easy/submit接口合成视频:audio_url: 上传的合成音频文件名video_url: 上传的静音视频文件名code,chaofen,watermark_switch,pn: 保持默认值即可
-
点击 Send,开始视频合成。
-
使用 Hoppscotch 调用
easy/query接口查询视频合成进度。
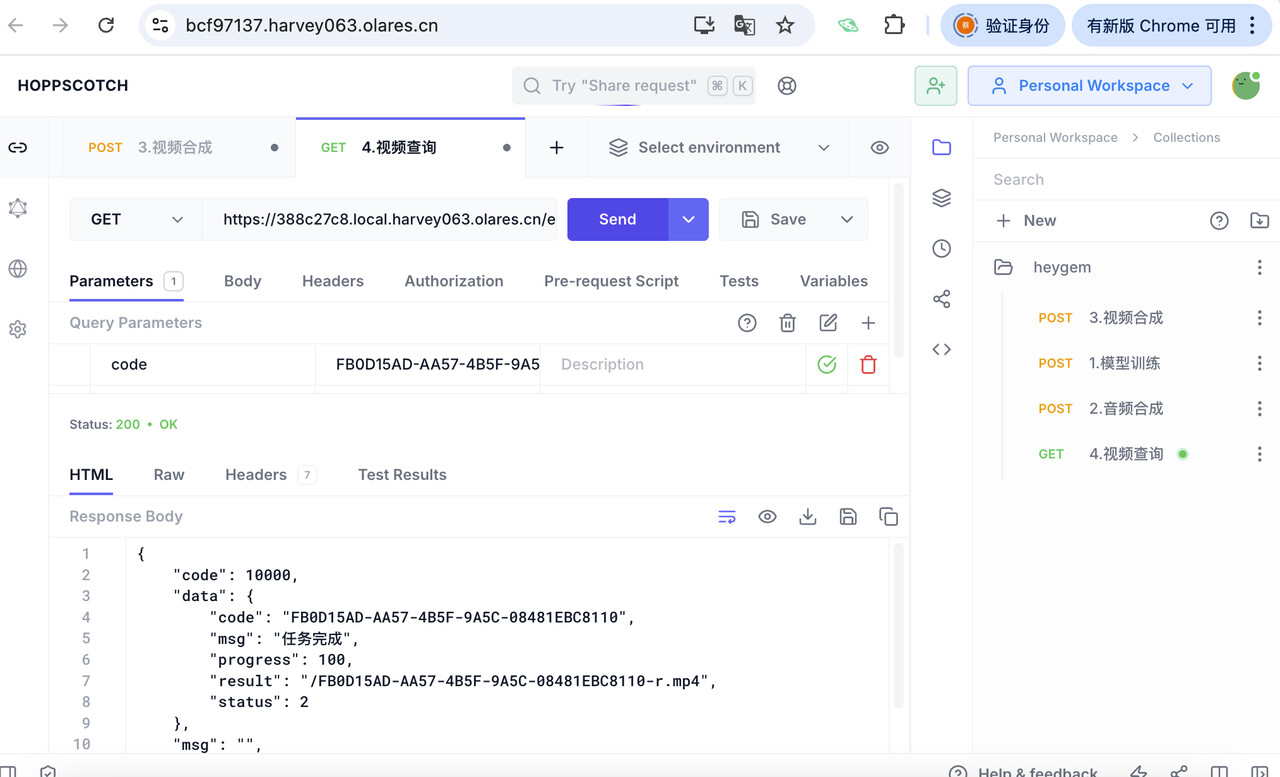
返回包含合成进度信息的 JSON。当 status 为 2 且 msg 为 “任务完成” 时,result 字段包含生成的最终视频文件路径。
