Duix.Avatar(前身为 Heygem 项目)是一个开源的 AI 数字人生成工具包,专注于离线视频生成和数字人克隆。通过本教程,你将学习如何在 Olares 平台中部署和使用 Duix.Avatar,完成从模型训练到视频合成的全过程,最终生成由文本驱动的数字人视频。
目标
通过本教程,你将学习:
-
准备和处理用于数字人克隆的视频和音频素材。
-
在 Olares 上使用 Hoppscotch 调用 Duix.Avatar 的系列 API,完成模型训练、音频合成和视频合成。
准备工作
在开始之前,请确保满足以下条件:
-
当前运行 Olares 的设备配备有 NVIDIA GPU。
-
已安装 Olares 1.11 或更高版本。
安装 Duix.Avatar 与 Hoppscotch
除里 Duix.Avatar,我们还需要从 Olares 应用市场安装其 API 请求工具 Hoppscotch。Hoppscotch 是一款类似于 Postman 的开源 API 开发环境,我们将用它来与 Duix.Avatar 服务进行交互。
-
打开 Olares 应用市场,左侧导航栏点击搜索。
-
输入应用名称,依次安装 Duix.Avatar 与 Hoppscotch。
准备素材文件
数字人视频的生成需要一份源视频作为“面孔”和“声音”的模板。你需要准备一段正面、清晰、有人物开口讲话的视频,时长建议在 10-20 秒左右。
下一步需要将源视频分离为静音视频和音频文件,你可以使用任何熟悉的音视频处理工具来完成。在本教程中,我们将使用ffmpeg作为示例。
确保 ffmpeg 已安装 如果你希望跟随本教程使用
ffmpeg命令行,请确保它已在你的本地计算机上安装。参考 https://www.ffmpeg.org/download.html。
-
下载源视频后,使用
ffmpeg命令将其分离为静音视频(output_video.mp4)和 WAV 格式的音频(output_audio.wav)。这两个文件将分别用作视频合成的画面基础和声音克隆的训练样本。 -
打开终端,使用
cd命令进入视频文件所在的文件夹,执行以下命令。# 将 input.mp4 替换为实际文件名 ffmpeg -i input.mp4 -c:v copy -an output_video.mp4 -c:a pcm_s16le -f wav output_audio.wav命令成功执行后,你会在同一个文件夹内看到两个新生成的文件:
-
output_video.mp4(静音视频) -
output_audio.wav(音频)
-
-
Duix.Avatar 的后台服务会从特定的挂载目录中读取文件。你需要将上一步生成的两个文件上传到 Olares 文件管理器中的指定位置。
- 将音频文件
output_audio.wav上传到以下路径:
/数据/heygem/voice/data/- 将视频文件
output_video.mp4上传到以下路径:
/数据/heygem/face2face-data/temp/ - 将音频文件
导入 API 示例到 Hoppscotch
为了方便调用,我们提供了一个预设的 Hoppscotch API 集合。
-
在终端中运行以下命令,以下载 API 集合文件:
curl -o duix.json https://cdn.olares.cn/app/demos/duix/duix.json -
在 Olares 中打开已安装的 Hoppscotch 应用。
-
在右侧集合面板点击导入 > 从 Hoppscotch 导入,然后选择刚刚下载的
duix.json文件。
导入后,你将在右侧看到名为heygem的 API 集合,其中包含了四个预设的请求。
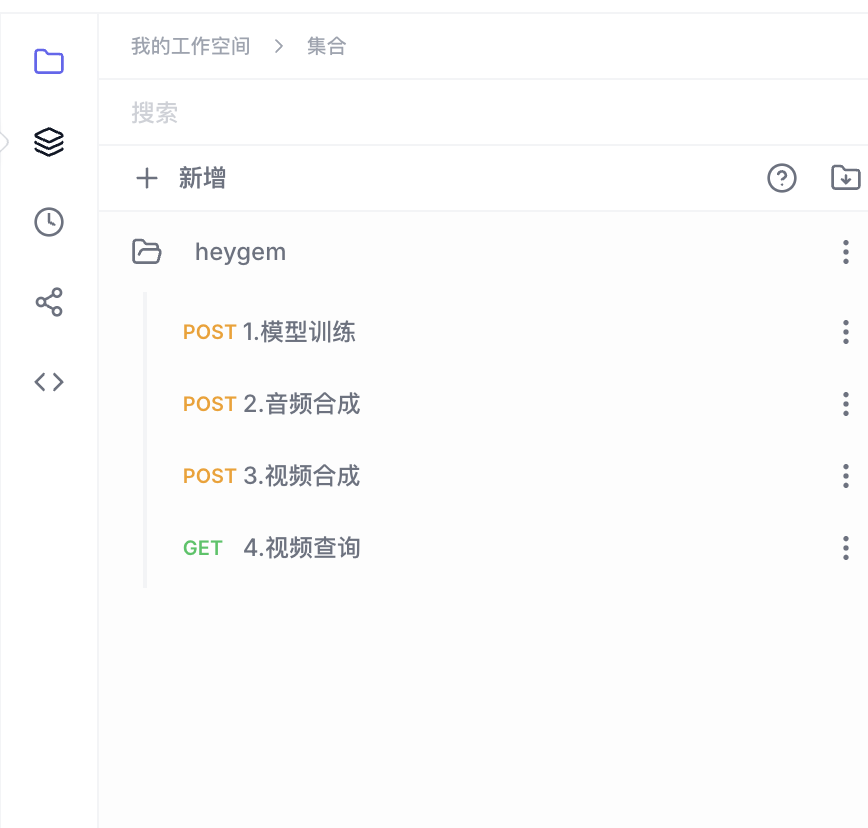
通过 API 训练数据
现在,我们将依次调用四个 API 来完成数字人视频的生成。
提示
Duix.Avatar 的 API 地址与你的 Olares ID 相关联。在以下所有 API 请求中,你都需要将 URL 中的
harvey063替换为你自己的 Olares ID 前缀。例如,如果你的 Olares 访问地址是https://app.alice123.olares.cn,那么你的 Olares ID 前缀就是alice123。
模型训练
此步骤用于对你上传的音频进行预处理和特征提取,为声音克隆做准备。
-
在 Hoppscotch 中,展开
heygem集合,点击1.模型训练请求。 -
修改请求 URL,将
harvey063替换为你的 Olares ID。注意
请求体中的参数已预设为指向你上传的
output_audio.wav文件,无需修改。 -
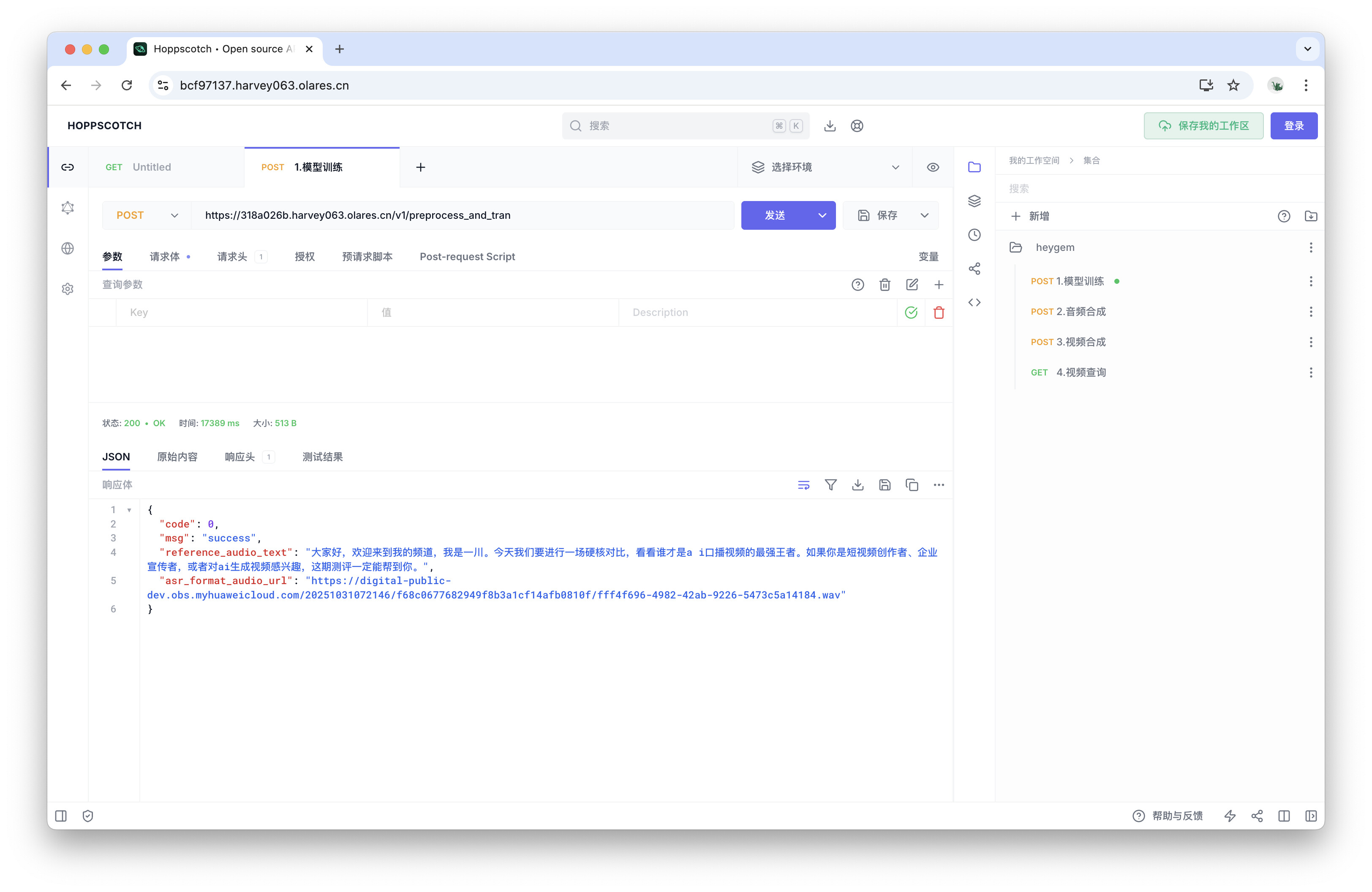
点击发送,进行数据预训练。
请求成功后,你会收到一个 JSON 格式的响应。响应中的reference_audio_text和asr_format_audio_url字段的值,它们将在下一步“音频合成”中使用。
音频合成
此步骤将根据你提供的文本,使用上一步训练好的声音模型来合成新的音频。
-
点击
2.音频合成请求。 -
修改请求 URL 中的 Olares ID。
-
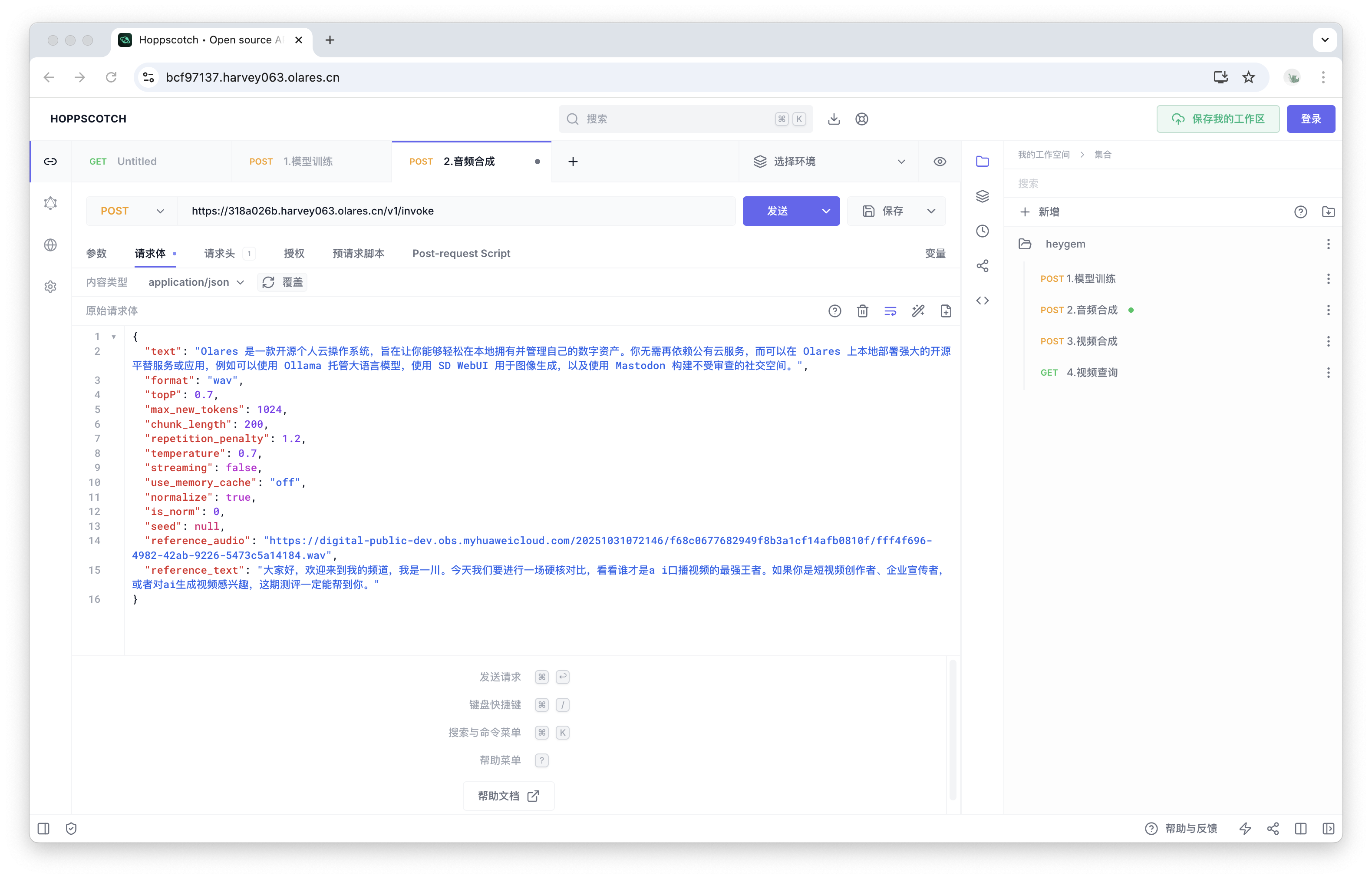
在请求体中,修改以下字段:
-
text:填入你希望数字人朗读的文本内容。 -
reference_audio:填入上一步“模型训练”响应中获得的asr_format_audio_url值。 -
reference_text:填入上一步“模型训练”响应中获得的reference_audio_text值。 -
其余参数可保持默认值。
-
-
点击发送,进行音频合成。
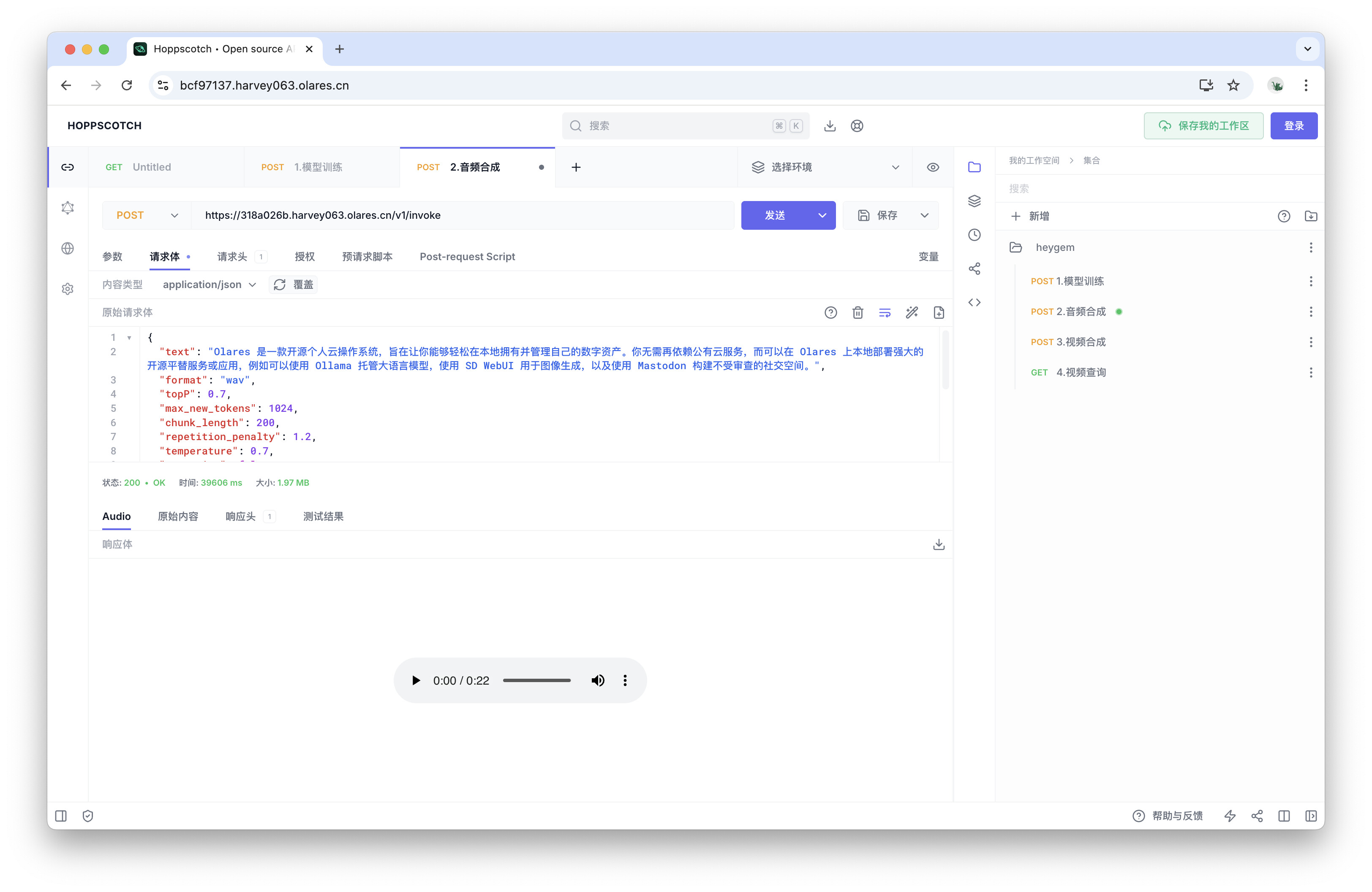
-
请求成功后,响应将是一个音频文件。在响应区域点击“更多”图标下载音频,默认为
.mp3格式。 -
将该音频文件重命名为
new.mp3,并在其所在文件夹打开终端,使用ffmpeg转换为.wav格式:ffmpeg -i new.mp3 new.wav -
将下载好的
new.wav文件上传到文件管理器的以下路径:/数据/heygem/face2face-data/temp/
视频合成
现在,我们将合成的音频与之前准备的静音视频进行合并,生成最终的数字人视频。
-
点击
3.视频合成请求。 -
修改请求 URL 中的 Olares ID。
-
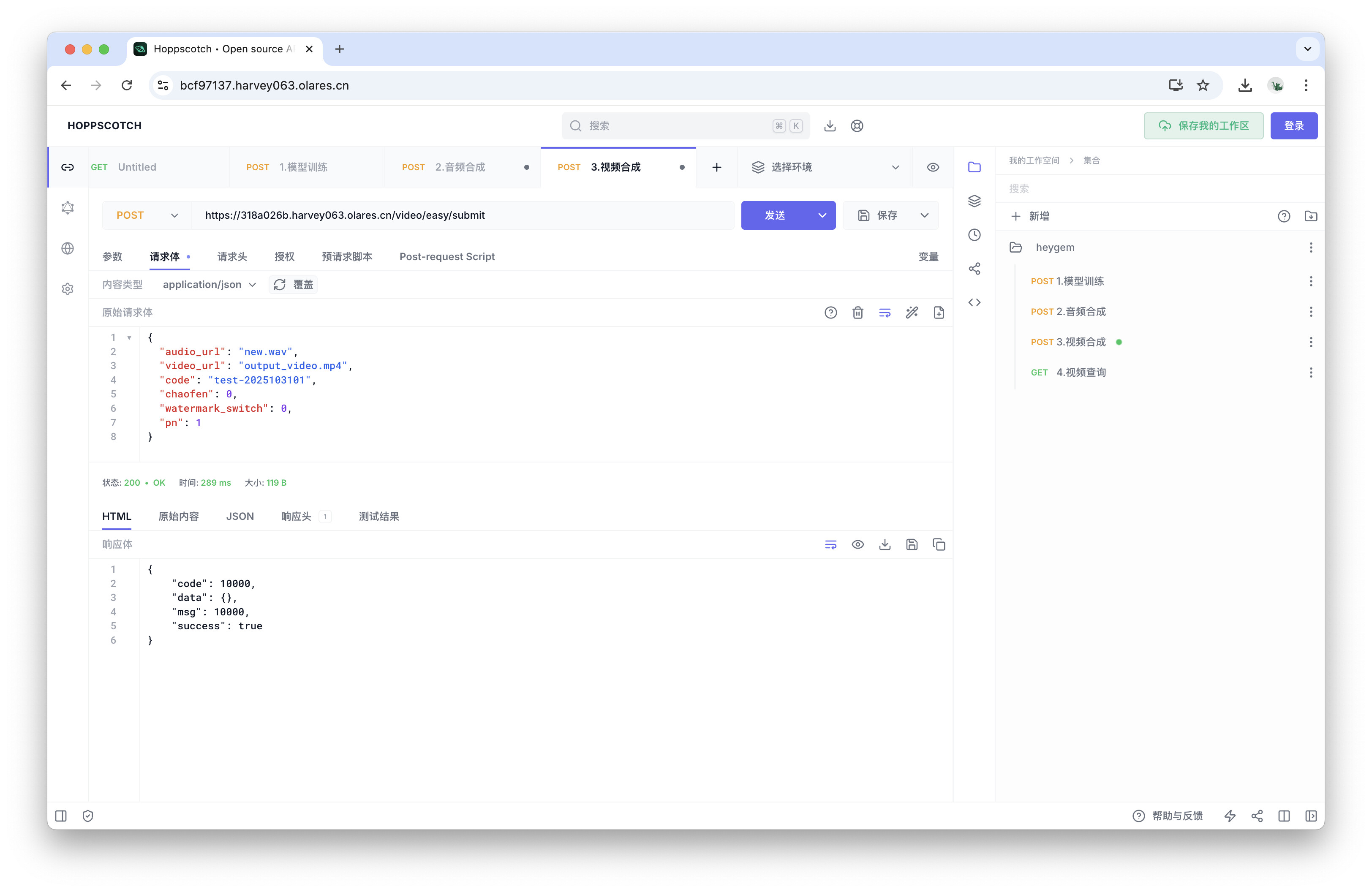
在请求体中,修改
code字段的值,它是一个唯一的任务标识符,用于后续查询合成进度。注意
在请求体中,
audio_url和video_url的值已预设为new.wav和output_video.mp4,与我们之前上传的文件名一致,因此无需修改。 -
确认无误后,点击发送按钮。成功后会返回
"succuess": true表示任务已提交。
查询视频合成进度
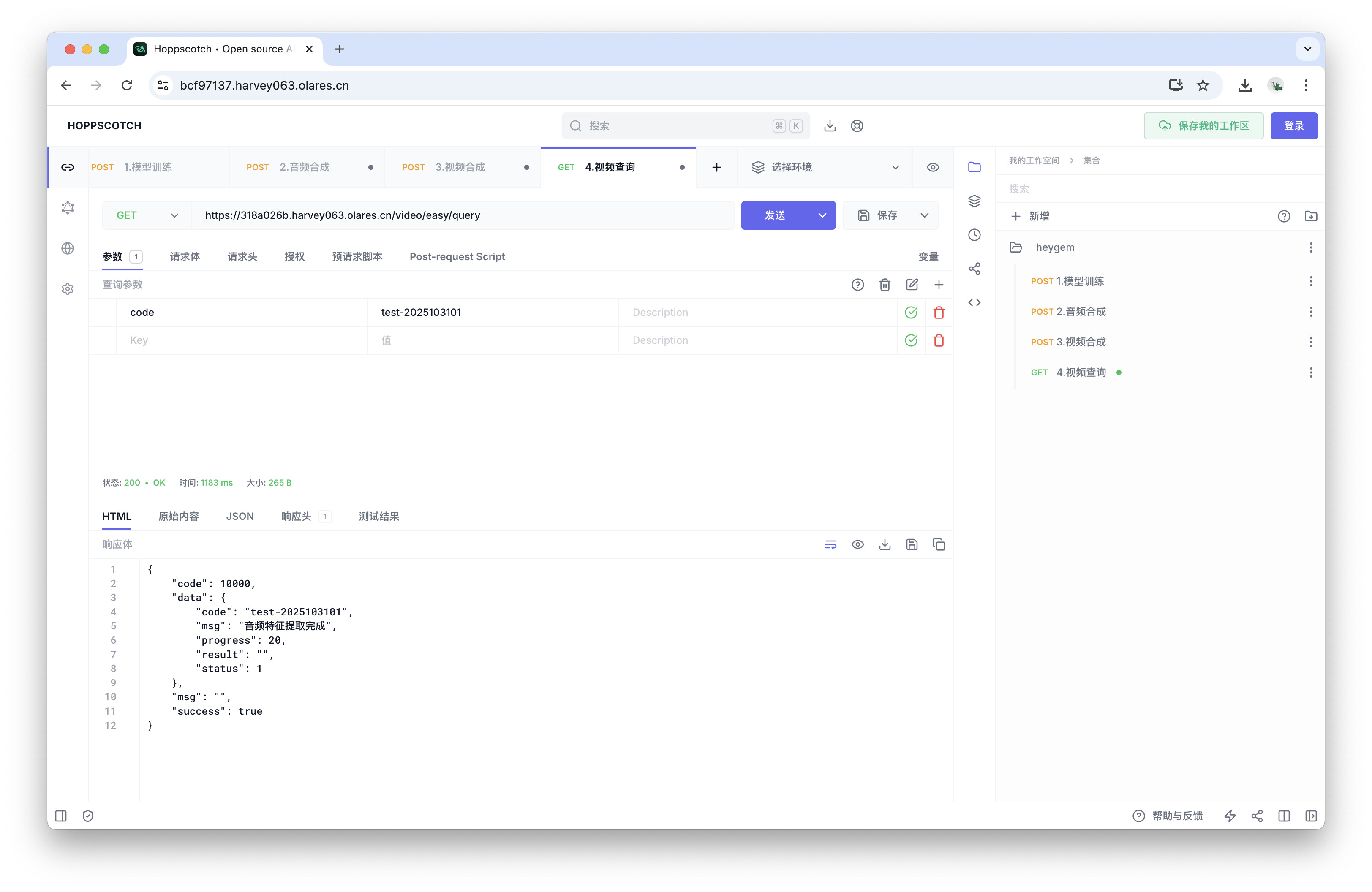
视频合成是一个耗时任务,你可以通过此接口查询其处理进度。
-
点击
4.视频查询请求。 -
修改请求 URL 中的 Olares ID。
-
在参数部分,将
code的值修改为你在上一步“视频合成”时设置的唯一标识符。 -
点击发送按钮,查看当前进度。
-
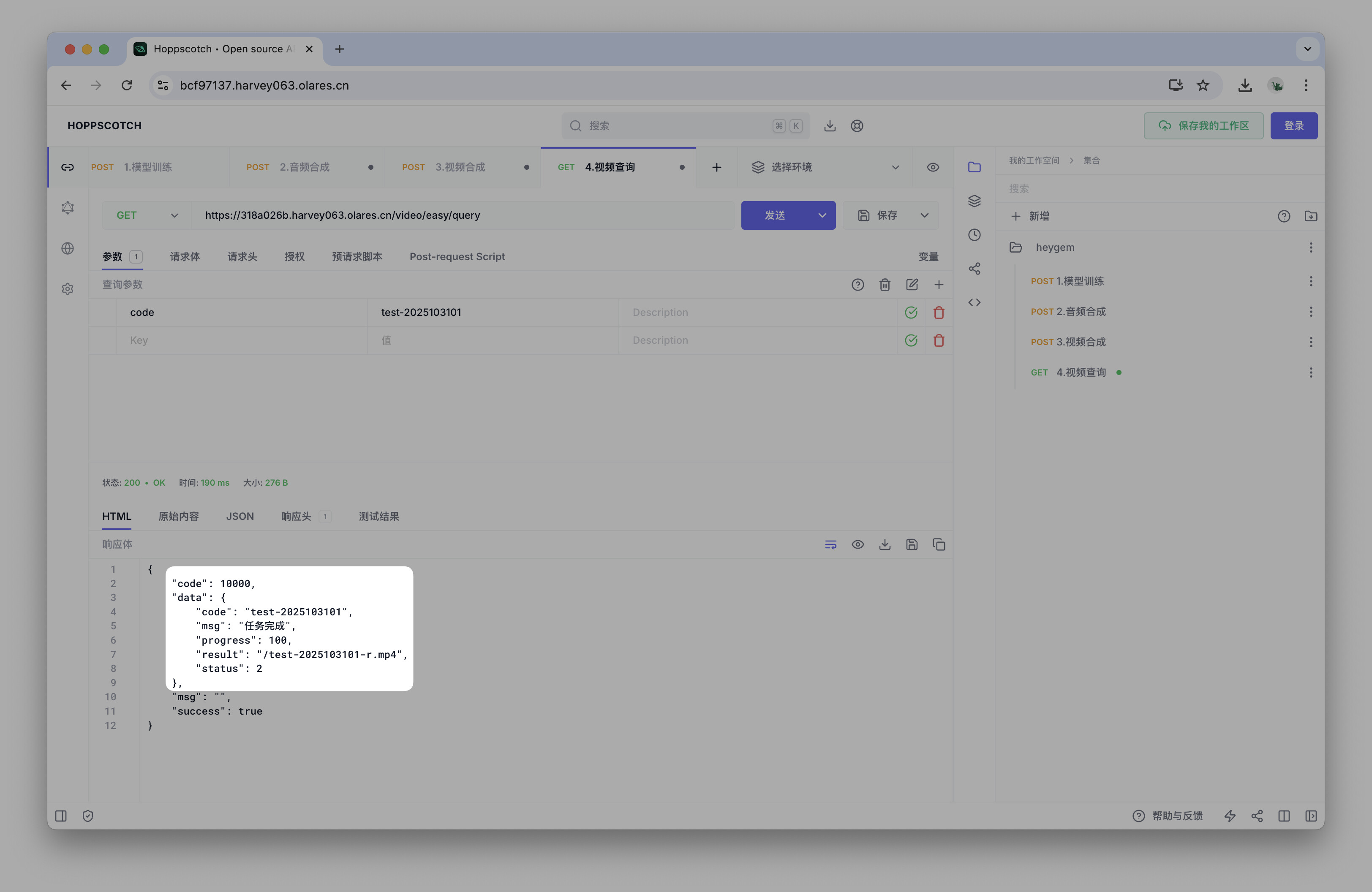
重复查询,直到响应中的
progress字段达到100,即代表视频合成成功。提示
视频合成所需时间取决于你的 GPU 性能和视频长度,可能需要数分钟或更长时间。
-
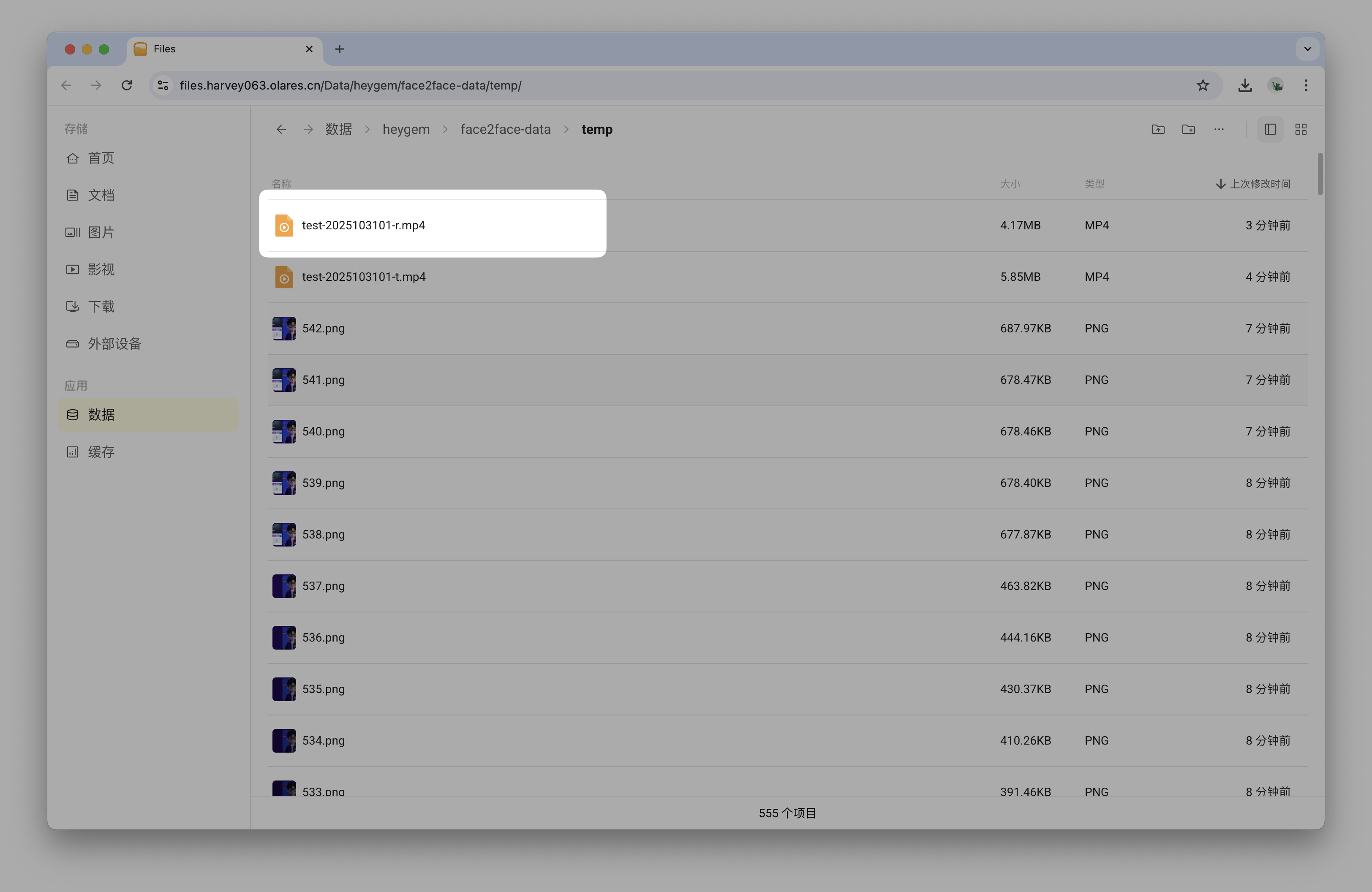
合成成功后,响应中的
result字段会指明输出视频的名称。你可以在 Olares 文件管理器中找到生成的最终视频文件,文件路径为:/数据/heygem/face2face-data/temp/
常见问题
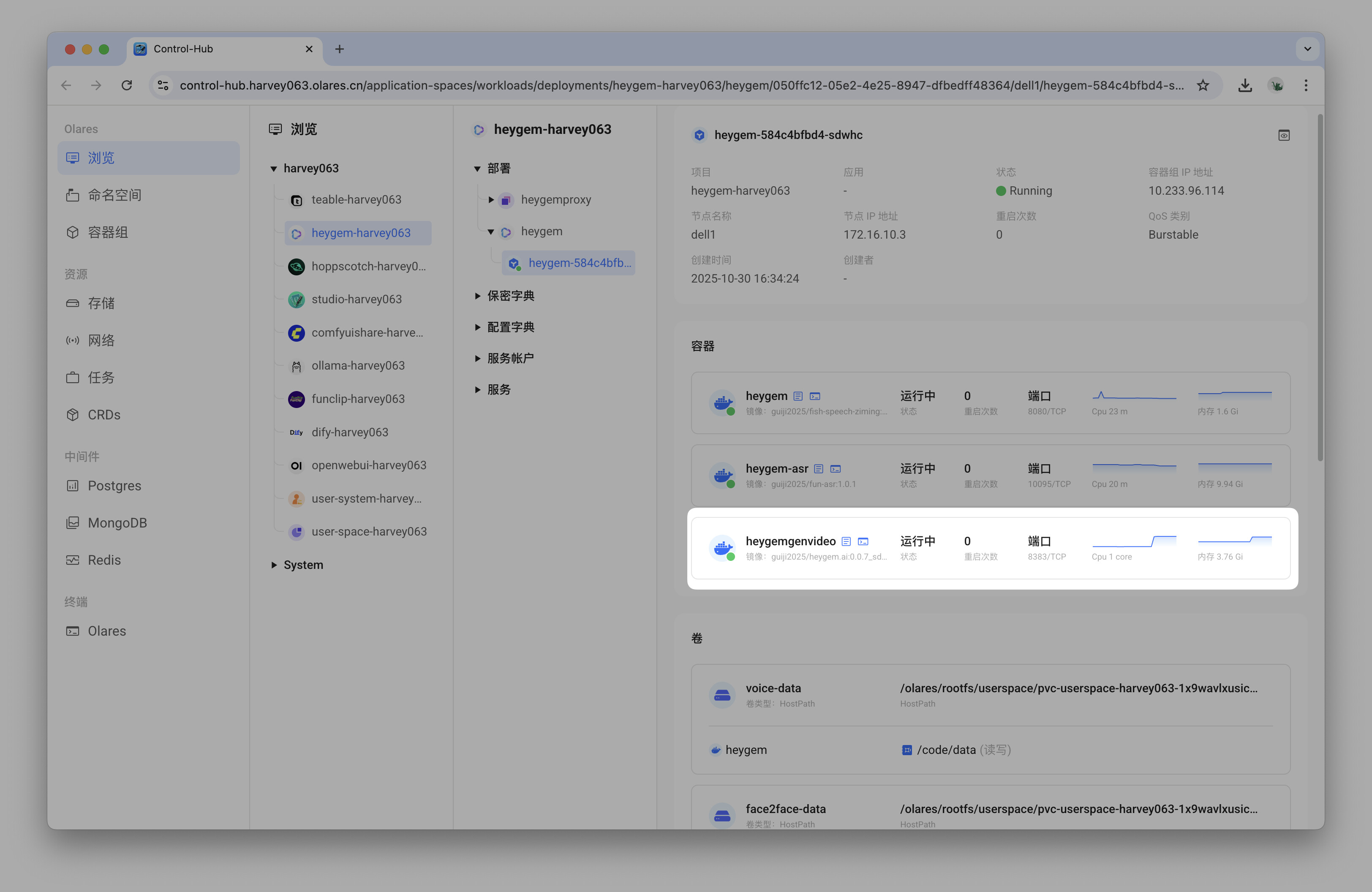
长时间进度不变或合成失败
如果查询进度长时间停滞不前,或 API 返回错误,前往 Olares 控制面板,找到名为heygemgenvideo的容器,并查看其日志,以获取详细的错误信息。
API 请求失败
请确认:
-
是否已将 API 请求 URL 中的 Olares ID(
harvey063)正确替换为你自己的 ID。 -
所有素材文件(
output_audio.wav,output_video.mp4,new.wav)是否已上传到指定的正确目录,并且文件名无误。
素材已更新,但是生成的数字人视频还是旧的
请确认在新的“视频合成”任务中,使用了全新的code参数。
系统会缓存任务结果,重复使用code会直接返回已缓存的旧视频。