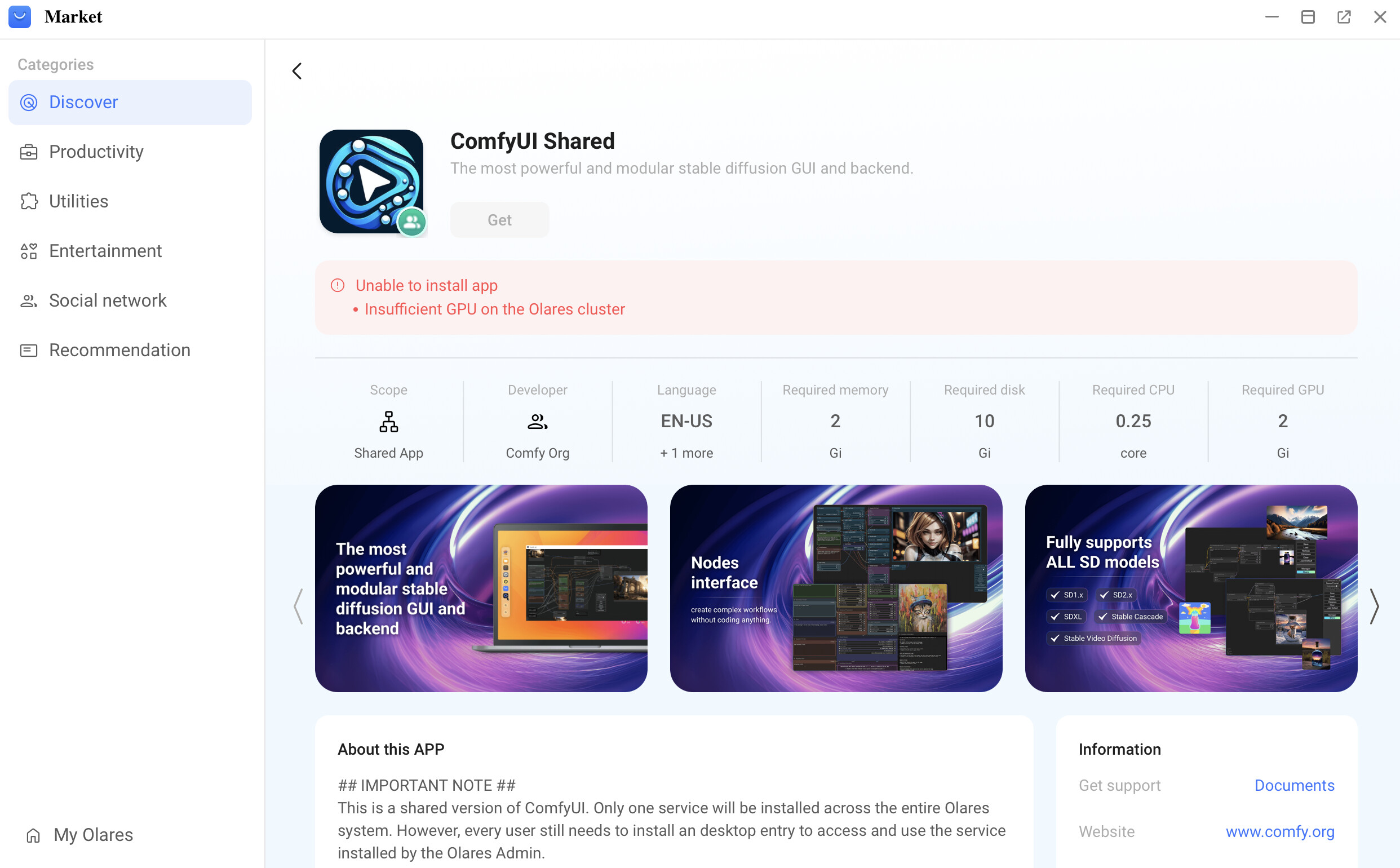
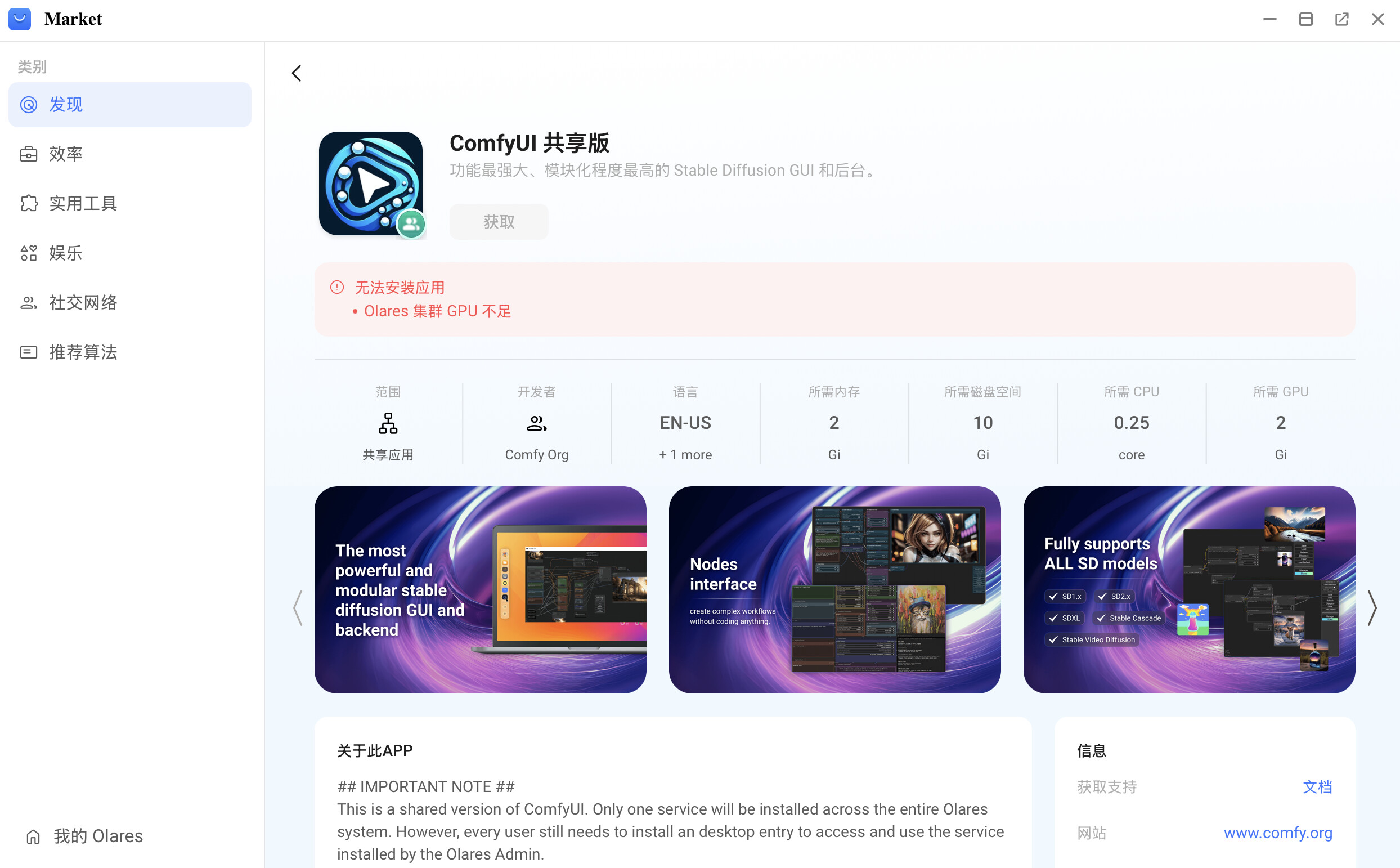
现象
在Market中,GPU应用的“获取”按钮置灰,无法点击,且错误提示“集群GPU不足”
排查路径
说明
以下排查路径为递进顺序,确认前项无问题后再进行下一项
文档无法覆盖所有可能的情况,若全部执行完成,问题仍未解决,在开发人员协助排查前,请将每个步骤的排查结果及命令输出一并整理并提交在评论区,便于其他用户检索及解决问题,也便于本文档的持续完善
文档对提及的技术概念不作展开解释,若需要理解请自行查阅研究
目前,Olares只支持英伟达显卡,且50系列只在1.12版本中支持。注意,显卡在开始安装Olares之前就已插入,才会在安装过程中安装驱动,若显卡在安装完成Olares后才插入,需手动执行sudo olares-cli gpu install安装驱动
在命令行中执行以下命令
lspci | grep -i vga | grep -i nvidia
若命令输出类似:
01:00.0 VGA compatible controller: NVIDIA Corporation AD106 [GeForce RTX 4060 Ti] (rev a1)
则说明Linux在硬件层面已识别到该显卡
注意该输出中最后的(rev a1)部分,若该值为(rev ff),则说明虽然能检测到该显卡硬件,但它已停止运行,可能的原因有电源、线路、散热问题等,需进一步排查
若命令输出为空,则需要检查主板、显卡PCIE接口等硬件问题
在命令行中执行以下命令
nvidia-smi
若命令输出类似:
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 570.133.20 Driver Version: 570.133.20 CUDA Version: 12.8 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA GeForce RTX 4060 Ti Off | 00000000:01:00.0 Off | N/A |
| 0% 37C P8 6W / 165W | 4MiB / 16380MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
+-----------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
则说明显卡驱动已安装且正常运行
若命令行报错command not found: nvidia-smi,则说明显卡驱动未安装,需手动执行sudo olares-cli gpu install安装驱动
若命令输出类似:
Unable to determine the device handle for GPU 0000:01:00.0: Unknown Error
则该问题与第2步中输出为(rev ff)的情况类似,需进一步排查
若命令输出类似:
Failed to initialize NVML: Driver/library version mismatch
说明当前Linux内核中运行的英伟达驱动版本与Olares安装的版本不匹配,需重启机器
若命令输出类似:
NVIDIA-SMI has failed because it couldn't communicate with the NVIDIA driver. Make sure that the latest NVIDIA driver is installed and running.
则执行命令:
sudo dpkg -l | grep nvidia-driver
若命令输出为空,则说明显卡驱动未安装,需手动执行sudo olares-cli gpu install命令安装
若命令输出类似:
ii nvidia-driver-570 570.133.20-0ubuntu1 amd64 NVIDIA driver metapackage
则说明显卡驱动已安装,但并未正常运行,需重启机器
若重启机器后现象依旧,尝试执行命令modprobe nvidia,若输出结果类似modprobe: ERROR: could not insert 'nvidia': Key was rejected by service,则可能是机器的BIOS启用了Secure Boot导致Linux内核无法加载显卡驱动模块,需查询机器BIOS如何关闭Secure Boot并配置生效
在命令行中执行以下命令
grep nvidia /etc/containerd/config.toml
若命令输出类似
default_runtime_name = "nvidia"
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.nvidia]
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.nvidia.options]
BinaryName = "/usr/bin/nvidia-container-runtime"
则说明显卡驱动支持在容器运行时中已启用
若命令输出为空,则说明显卡驱动支持在容器运行时中未启用,需手动执行sudo olares-cli gpu install命令
在命令行中执行以下命令
sudo olares-cli gpu status
若命令输出类似
2025-05-13T11:04:39.115+0800 GPU Driver Version: 570.144
2025-05-13T11:04:39.115+0800 CUDA Version: 12.8
2025-05-13T11:04:39.120+0800 nvidia-device-plugin status: Running
2025-05-13T11:04:39.122+0800 nvshare-device-plugin status: Running
2025-05-13T11:04:39.123+0800 nvshare-scheduler status: Running
注意输出中的Running字样,说明显卡驱动组件在K8s集群中已启用并正常运行
若命令输出类似
2025-05-13T11:05:17.509+0800 GPU Driver Version: 570.144
2025-05-13T11:05:17.509+0800 CUDA Version: 12.8
2025-05-13T11:05:17.515+0800 nvidia-device-plugin not exists
2025-05-13T11:05:17.516+0800 nvshare-device-plugin not exists
2025-05-13T11:05:17.517+0800 nvshare-scheduler not exists
注意输出中的not exists字样,说明显卡驱动组件在K8s集群中没有运行,需手动执行sudo olares-cli gpu enable命令后再次观察
若执行sudo olares-cli gpu enable后not exists仍存在,或者变更为Pending,在命令行中执行以下命令
kubectl get node
命令输出类似
NAME STATUS ROLES AGE VERSION
node1 Ready control-plane,master,worker 18h v1.32.2+k3s1
注意其中的Ready字样,若该字段为NotReady,说明机器存在异常,需进一步排查,常见原因为磁盘或内存压力等问题
若该字段为Ready,说明机器本身无异常,需进一步排查
请求开发人员协助排查
首先,请确保上一节中的每一项都已依次排查并按指导尝试修复
若问题仍未解决,请将排查项中的所有输出,即以下命令的输出,一并整理并提交给开发人员协助排查
lspci | grep -i vga | grep -i nvidia
nvidia-smi
sudo dpkg -l | grep nvidia-driver
grep nvidia /etc/containerd/config.toml
sudo olares-cli gpu status
kubectl get node